D1:大模型 API 基础
Easy Data x AI 课程 · 开发者路径 · 第一期
从这节课开始,“术篇”会和“道篇”分开。“术篇”中的每一节课都会动手跑上几行示例代码——不是教你背 API 文档,而是帮你建立“用代码控制 AI”的工程直觉。
在“术篇”的课程中,我们每期都会附带几个 python 文件(例如本文对应的几个
d1_n_xxx.py),填上你的 API Key 就可以直接运行。
本期课程视频
本期课程使用 LangChain(langchain-openai)作为开发框架。LangChain 是目前最流行的大模型应用开发框架之一,它在原生 OpenAI SDK 之上提供了更高层的抽象——统一的模型接口、标准化的工具调用、便捷的流式处理——让你用更少的代码做更多的事。更重要的是,当你未来需要切换模型供应商(从 OpenAI 换到 Anthropic、Google 等),LangChain 的代码几乎不用改。
本期课程涉及的代码,均在 https://github.com/ob-labs/easy-data-x-ai 项目的 code 目录中(欢迎大家 star 和参与课程共建)。
# ============================================================
# 示例代码简介:从 d1_1 到 d1_6 的演进
#
# d1_1 基础调用 → 用代码调用大模型(一问一答)
# d1_2 多轮对话 → 手动维护消息历史
# d1_3 流式输出 → 提升用户体验
# d1_4 Tool Use Mock → 手动编排工具调用流程(假数据)
# d1_5 Tool Use Real → 手动编排 + 真实向量检索(seekdb)
# d1_6 Agent 循环 → 自动化的"推理→行动→观察"多轮循环
#
# d1_4/d1_5 中你手动写的那些 if/else 逻辑,
# 在 d1_6 中被 create_agent 一行代码替代了!
#
# create_agent 底层基于 LangGraph,自动处理了:
# 1. 把工具绑定到模型
# 2. 调用模型,检查是否有 tool_calls
# 3. 如果有,执行工具,把结果以 role:"tool" 格式传回
# 4. 循环直到模型给出最终回答
#
# 这就是 F2 中说的:
# "Agent 不是'一个更聪明的 ChatGPT',
# 而是一个具有'感知→推理→行动'循环能力的系统。"
# ============================================================复制
.env.example为.env,并在.env文件中填写你的真实 API Key,即可直接执行对应章节的示例代码。推荐大家可以通过在硅基流动上注册账号,获取 API 密钥,使用免费模型
tencent/Hunyuan-MT-7B或者deepseek-ai/DeepSeek-OCR来亲自体验一下。
cd easy-data-x-ai/code
# 安装依赖
pip install --upgrade -r requirements.txt
# 复制 .env.example 为 .env
cp .env.example .env
# 在 .env 文件中填写你的真实 API Key
vim .env
# 运行示例代码
python D1/d1_1_base.py开场:从“用嘴说”到“写代码控制”
你大概率已经是 ChatGPT 或 Claude 的熟练用户了。打开网页,输入问题,等待回答。有时候你还会精心设计 Prompt,试图让 AI 的回答更准确、更符合你的要求。
但如果你要做一个 AI 产品——哪怕只是一个内部工具——光会在网页上聊天是不够的。
想象一下:你要做一个客服助手,它需要在用户提问时自动去查你的知识库,然后基于查到的内容回答。这件事你没法在 ChatGPT 的聊天框里完成——你总不能让客服 Agent 自己在浏览器里打开另一个标签页,手动去搜索吧?
要做到这件事,你需要两个能力:
- 用代码调用大模型——不是通过网页,而是通过 API,用程序化的方式控制模型的输入和输出
- 让模型能“做事”,而不只是“说话”——模型不只是回答问题,还能触发你的代码去执行操作(比如查数据库、调接口)
这两个能力,就是今天这节课的全部内容。第一个是通过 LangChain 调用 Chat 模型,第二个是 Tool Use。
其中 Tool Use 是重点中的重点。理解了它,你就理解了 Agent 与外部世界交互的核心机制——后续所有模块的 Agent 能力,都建立在这个机制之上。
第一部分:用 LangChain 调用 Chat 模型——对话的本质是一个列表
Messages:一切都是消息
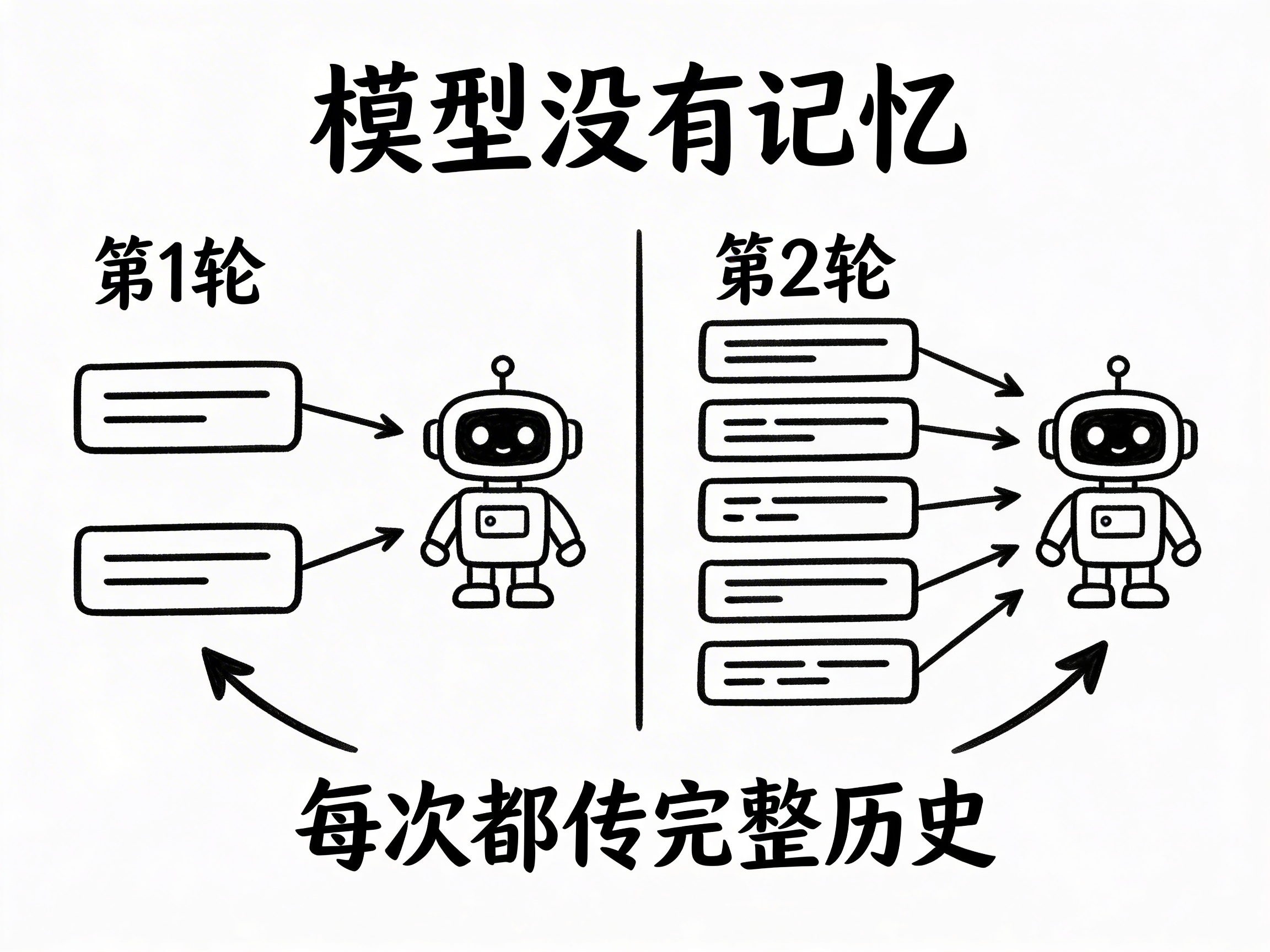
当你在 ChatGPT 网页上聊天时,背后发生的事情其实非常简单:你的每一句话和 AI 的每一句回复,都被组织成一个消息列表(messages array),整个列表一起发送给模型。
模型并不“记得”之前说了什么——它每次收到的都是一个完整的消息列表,然后基于这个列表生成下一条回复。所谓的“多轮对话”,不过是每次把历史消息重新发一遍。
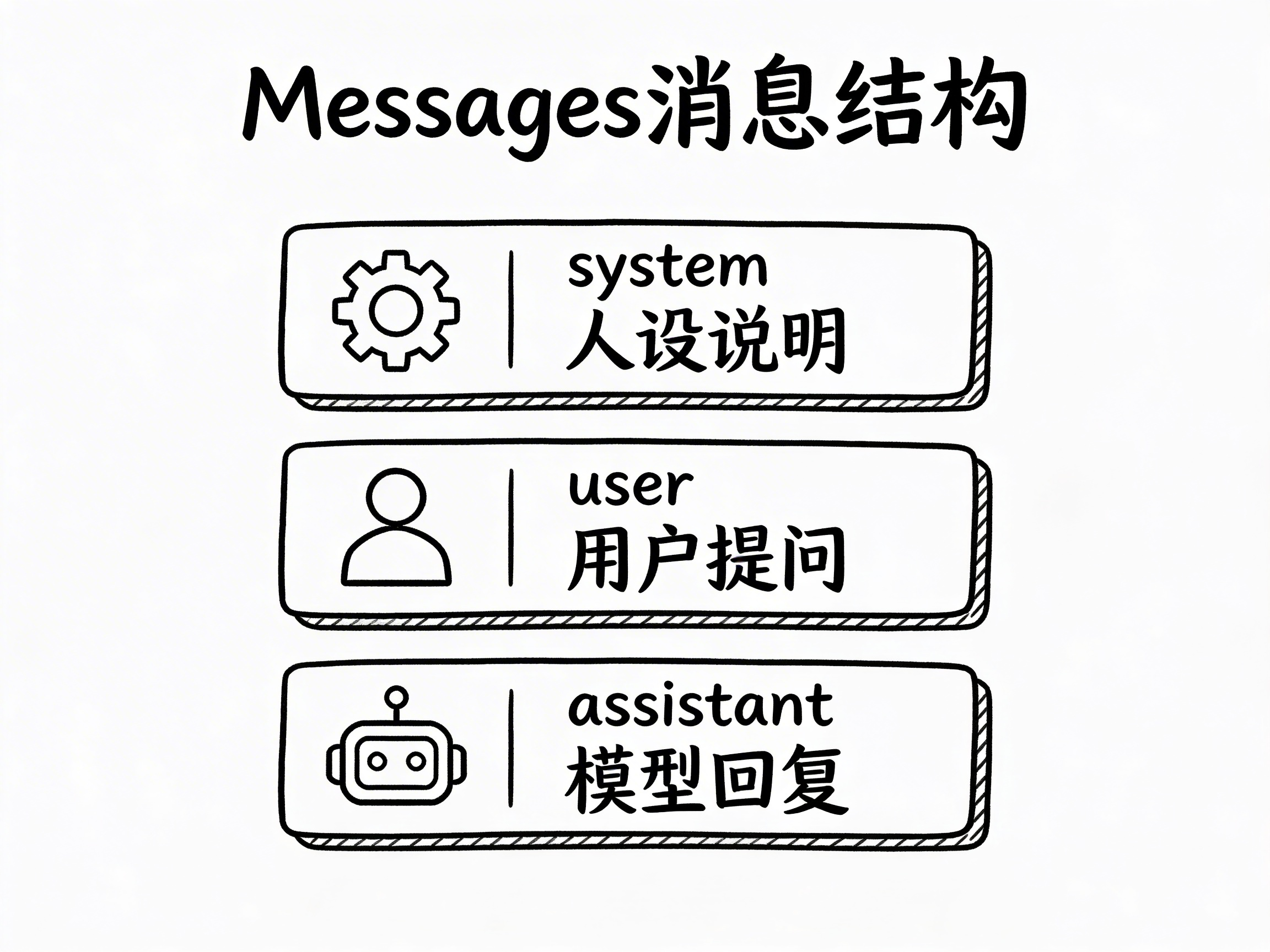
每条消息有两个核心字段:角色(role)和内容(content)。角色有三种:
| 角色 | 含义 | 类比 |
|---|---|---|
system | 给模型的“人设说明”——你是谁、你该怎么做 | 你给新同事的第一天入职指南 |
user | 用户说的话 | 客户的提问 |
assistant | 模型的回复 | 你(作为同事)给出的回答 |
其中 System Prompt 是你控制 Agent 行为的核心杠杆。你希望 AI 回答时用中文还是英文?语气正式还是轻松?遇到不确定的问题是坦诚说不知道还是硬猜一个?这些都在 System Prompt 里控制。在后续模块中,你会看到 System Prompt 里可以携带多少信息——用户偏好、行为规则、领域知识——它本质上就是 F2 讲过的“程序记忆”的载体。
现在来看代码。在 LangChain 中,调用大模型 API 最基本的写法只有几行:
from langchain.chat_models import init_chat_model
llm = init_chat_model(
"tencent/Hunyuan-MT-7B",
model_provider="openai", # 通过 OpenAI 兼容接口调用
base_url="https://api.siliconflow.cn/v1",
api_key="YOUR_API_KEY",
)
response = llm.invoke([
("system", "你是一个简洁高效的技术助手。用中文回答,尽量用一两句话。"),
("user", "什么是 RAG?"),
])
print(response.content)和原生 OpenAI SDK 相比,LangChain 的写法有几个不同:
- 用
init_chat_model统一初始化模型,通过model_provider指定提供商 - 消息用元组格式
("role", "content"),比字典更简洁 - 调用方法是
llm.invoke(),返回的是一个AIMessage对象,用.content获取文本
这看起来只是语法糖,但 LangChain 的真正价值在后面——当你需要切换模型、组合工具、构建链式调用时,统一的接口会帮你省掉大量的适配代码。
如果你想做多轮对话,同样是把之前的消息追加到列表里再发一次:
from langchain.chat_models import init_chat_model
llm = init_chat_model(
"tencent/Hunyuan-MT-7B",
model_provider="openai",
base_url="https://api.siliconflow.cn/v1",
api_key="YOUR_API_KEY",
)
messages = [
("system", "你是一个简洁高效的技术助手。"),
("user", "什么是 RAG?"),
("assistant", "RAG 是检索增强生成,先从知识库检索相关内容,再让模型基于这些内容生成回答。"), # 让模型在回答你追问的下一个问题之前,知道你们之前聊了什么,知道下一个问题中的"它"是谁。
("user", "它和直接把文档塞进 Prompt 有什么区别?"),
]
response = llm.invoke(messages)
print(response.content)看到了吗?模型没有“记忆”。所谓的对话历史,全靠你自己维护这个消息列表。每次调用,你都要把完整的历史传过去。这正是 F1 讲过的“上下文窗口”在工程层面的体现——你能传多少历史消息,取决于窗口能装多少 Token。
第二部分:Streaming——为什么生产环境几乎都用流式输出
等 30 秒 vs 立刻开始看
你在 ChatGPT 网页上聊天的时候,有没有注意过一个细节?AI 的回答不是突然“啪”地一下全部出现的——它是一个字一个字地“打”出来的,就像对面有个人在实时打字一样。
这不是装的,这就是流式输出(Streaming)。
为什么要这么做?因为大模型生成一段完整回答可能需要几秒甚至十几秒。如果你让用户干等到最后一个字生成完毕才显示——用户会觉得系统卡死了。
但如果第一个字在 0.3 秒内就开始出现,即使整段回答要 10 秒才能生成完毕,用户的体感也完全不同——他在“看 AI 思考”,而不是在“等系统响应”。
这是一条重要的用户体验原则:
首 Token 延迟(Time to First Token)比总生成时间更重要。
用户对“等待”的容忍度远低于对“逐步呈现”的容忍度。这不是 AI 特有的——想想视频加载,你能接受边下边播,但不能接受下完再播。
在 LangChain 中,流式输出只需要把 invoke 换成 stream:
from langchain.chat_models import init_chat_model
llm = init_chat_model(
"tencent/Hunyuan-MT-7B",
model_provider="openai",
base_url="https://api.siliconflow.cn/v1",
api_key="YOUR_API_KEY",
)
for chunk in llm.stream([
("system", "你是一个技术助手。"),
("user", "用三句话解释什么是向量数据库。"),
]):
print(chunk.content, end="", flush=True)
print() # 最后换行区别就是 llm.stream() 替代 llm.invoke(),然后用一个循环逐块读取。每个 chunk 是一个 AIMessageChunk,里面的 .content 带着一小段新生成的文本(通常是一个或几个 Token),你拿到之后立刻显示给用户。
对比原生 SDK 的写法(需要手动设置 stream=True,然后从 chunk.choices[0].delta.content 里取值),LangChain 的流式处理更简洁直观。
在生产环境中,绝大多数 AI 应用都使用流式输出。如果你只记一条规则:凡是面向用户的 AI 回答,都应该用 Streaming。
本期课程中的代码仅为演示,多用 invoke/stream。生产环境中,默认使用异步方式的 ainvoke/astream。
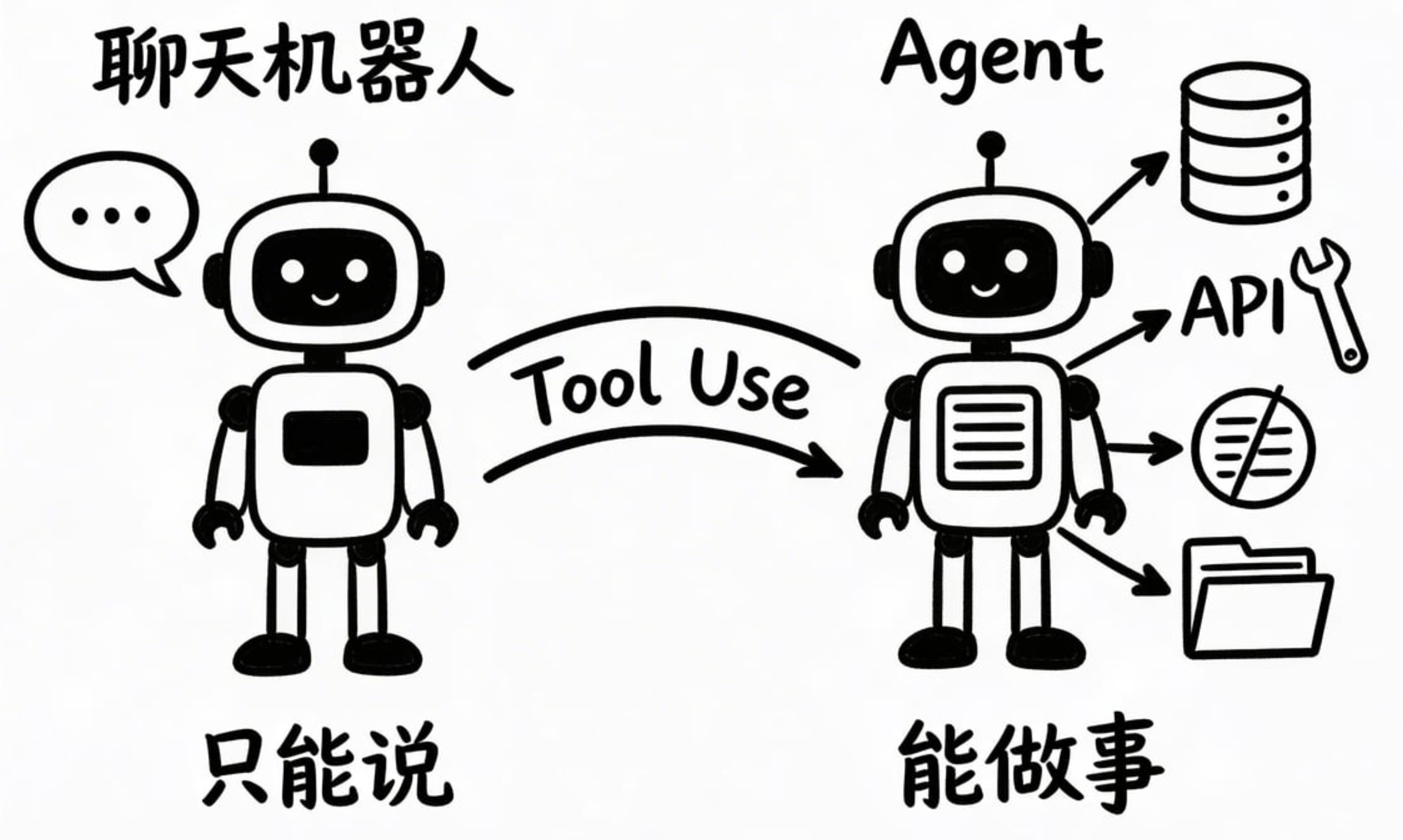
第三部分:Tool Use——让模型从“只能说”变成“能做事”
这是今天最重要的部分。前面讲的 API 调用和 Streaming 是基础设施;Tool Use 才是让 AI 产生质变的机制。
一个关键洞察
你有没有想过一个问题:ChatGPT 是怎么“上网搜索”的?它是怎么“生成图片”的?它是怎么“执行 Python 代码”的?
答案是:它自己做不了这些事。
大模型的能力只有一个:根据输入的文本,生成输出的文本。它不能上网,不能读文件,不能查数据库,不能调 API。它唯一能做的就是——说话。
那它是怎么“做事”的?
答案是 Tool Use(也叫 Function Calling)。
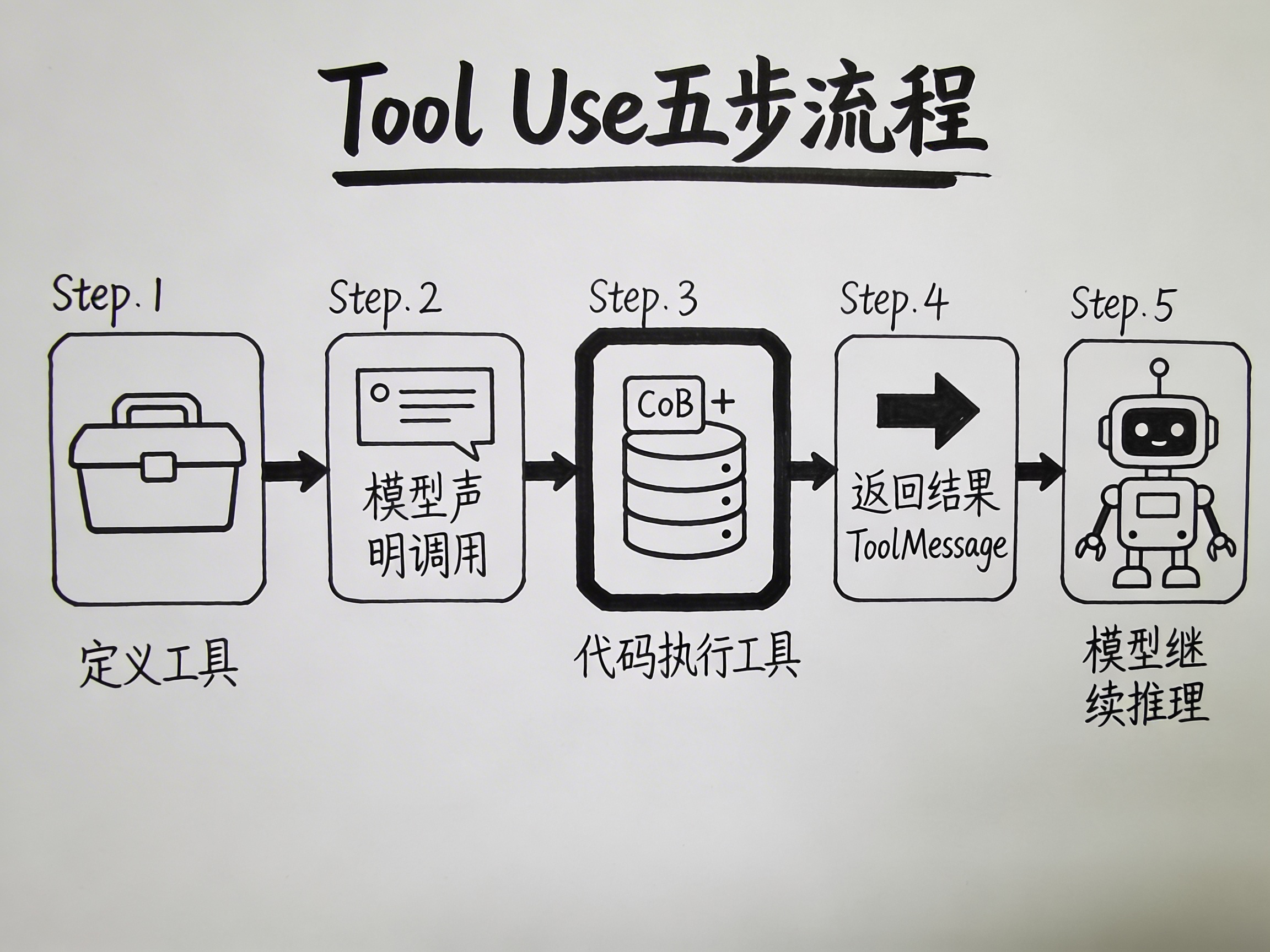
机制是这样的:
- 你告诉模型:“你有这些工具可以用”(定义工具)
- 模型分析用户的问题后,不直接回答,而是说:“我需要调用某个工具,参数是这些”(声明调用)
- 你的代码去执行这个工具调用,拿到结果(执行工具)
- 你把结果传回给模型(返回结果)
- 模型基于工具返回的结果,生成最终回答(继续推理)
请注意第 3 步——模型不执行工具,你的代码执行工具。模型只是“说”它想调用什么,真正干活的是你写的程序。模型是“指挥”,你的代码是“执行者”。
这个区分至关重要。它意味着:
- 模型能调用什么工具,完全由你定义
- 工具怎么执行,完全由你控制
- 执行结果怎么处理,完全由你决定
Tool Use 不是模型的“内置功能”——它是模型和你的代码之间的一个协作协议。
为什么说 Tool Use 是 Agent 的分界线
回到 F2 讲过的那个新员工类比。一个只会说话的新员工,充其量是个“顾问”——你问他问题,他给你建议。但一个能查公司系统、能操作工具、能帮你跑数据的新员工,才是一个真正能帮你做事的“同事”。
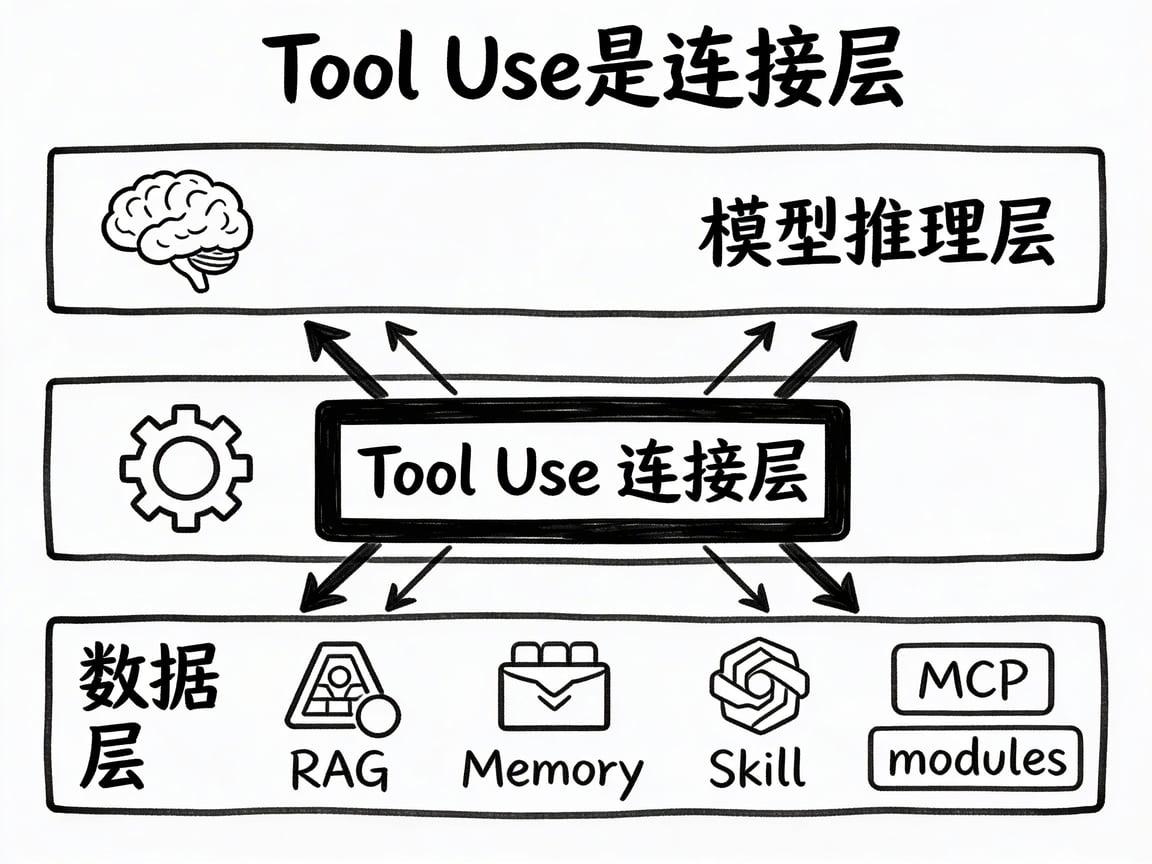
Tool Use 就是把大模型从“顾问”变成“同事”的机制。
- 没有 Tool Use → 模型只能基于它知道的东西回答 → 聊天机器人
- 有了 Tool Use → 模型可以决定去查数据库、调 API、执行操作 → Agent
F2 里讲的 Agent 四大能力——RAG、Memory、Skill、MCP——在工程实现上,全部依赖 Tool Use。Agent 怎么去“查知识库”?模型通过 Tool Use 声明“我要调用查询知识库的工具”,你的代码去执行检索,结果传回来。Agent 怎么“记住你”?模型通过 Tool Use 声明“我要把这条信息存入记忆”,你的代码去写入存储。
理解 Tool Use,就理解了 Agent 与外部世界交互的全部机制。
动手:一个完整的 Tool Use 例子
现在我们来写一个完整的 Tool Use 流程。场景很具体:用户问一个知识库相关的问题,模型自己判断需要查知识库,调用查询工具,基于查询结果回答。
我们用 seekdb 作为知识库的查询目标——它在后续模块会详细展开,这里你只需要把它当成一个“能用关键词和语义搜索的数据库”。
在 LangChain 中,Tool Use 的写法比原生 SDK 简洁很多。你不需要手动构造 JSON Schema,只需要用 Python 函数 + @tool 装饰器就行。
第一步:定义工具
在 LangChain 中,定义工具只需要写一个普通的 Python 函数,加上 @tool 装饰器:
from langchain_core.tools import tool
@tool
def query_knowledge_base(query: str) -> str:
"""从知识库中检索与用户问题相关的内容。当用户的问题涉及产品功能、技术文档、操作指南等需要查阅知识库的场景时使用。"""
# 这里调用你的知识库检索逻辑
return search_knowledge_base(query)对比原生 SDK 需要手写一大段 JSON Schema,LangChain 的方式更 Pythonic:
- 函数名就是工具名称
- **docstring **就是工具描述——模型根据这段描述来判断什么时候该用这个工具
- 参数类型注解自动转换为 JSON Schema——
query: str会被自动识别为字符串参数
description(也就是 docstring)极其重要。模型根据这段描述来判断什么时候该用这个工具。如果描述写得不清楚,模型就不知道什么时候该调用它。这和 System Prompt 一样,是你控制 Agent 行为的重要杠杆。
第二步:绑定工具,发起调用
from langchain.chat_models import init_chat_model
llm = init_chat_model(
"deepseek-ai/DeepSeek-V3",
model_provider="openai",
base_url="https://api.siliconflow.cn/v1",
api_key="YOUR_API_KEY",
)
# 把工具绑定到模型上
llm_with_tools = llm.bind_tools([query_knowledge_base])
# 发起调用
messages = [
("system", "你是一个技术文档助手。当用户问及产品相关问题时,请先查询知识库获取准确信息。"),
("user", "seekdb 支持哪些检索方式?"),
]
response = llm_with_tools.invoke(messages)注意 llm.bind_tools() 这一步——它把工具定义“绑定”到模型上,之后每次调用这个 llm_with_tools,模型都“知道”它有哪些工具可以用。
接下来模型会做一个判断:用户这个问题需不需要查知识库?如果用户问的是“1+1 等于几”,模型大概率直接回答,不会调用工具。但用户问的是“seekdb 支持哪些检索方式”——这是一个特定产品的具体功能问题,模型判断需要查知识库。
于是,模型不返回文本回答,而是返回一个 tool call——“我需要调用 query_knowledge_base,参数是 {"query": "seekdb 支持的检索方式"}”。在 LangChain 中,这个信息存在 response.tool_calls 里。
第三步:你的代码执行工具,结果传回模型
if response.tool_calls:
tool_call = response.tool_calls[0]
tool_name = tool_call["name"]
tool_args = tool_call["args"]
# 执行工具
result = query_knowledge_base.invoke(tool_args)
# 把工具调用结果传回模型
messages.append(response) # 先把模型的 tool_call 消息加进去
messages.append(ToolMessage(content=result, tool_call_id=tool_call["id"]))
# 模型基于工具返回的结果生成最终回答
final_response = llm.invoke(messages)
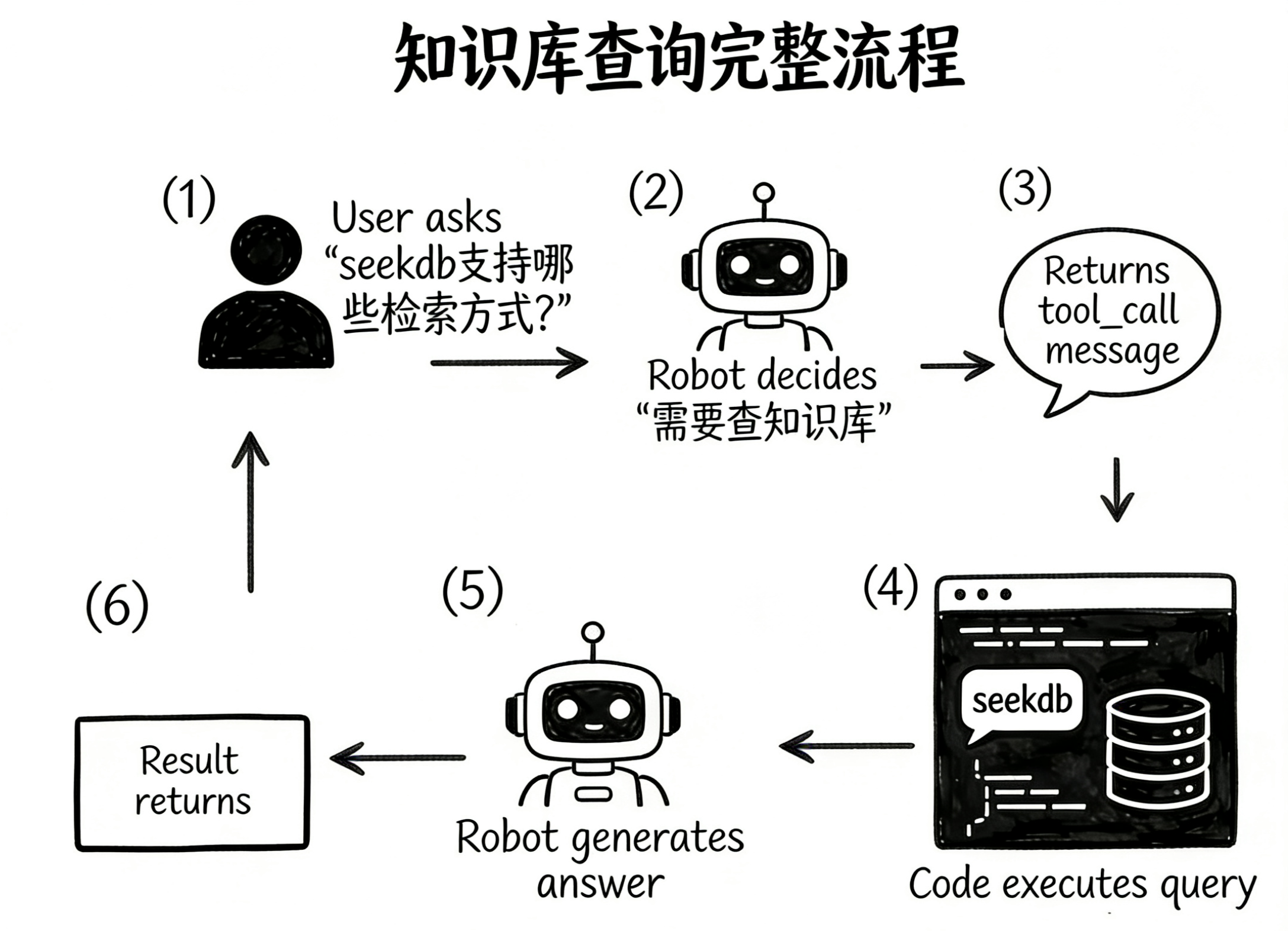
print(final_response.content)来看看整个流程中发生了什么:
- 用户问了一个问题
- 模型判断需要查知识库,返回 tool call(而不是直接回答)
- 你的代码拿到 tool call,执行实际的知识库查询(
query_knowledge_base.invoke()) - 查询结果作为
ToolMessage传回给模型 - 模型拿到查询结果后,基于这些真实数据生成最终回答
这就是一个完整的 Tool Use 循环。用 F1 的语言来说——模型不再“猜”答案了,因为你给了它一条路去获取真实数据。
对比原生 SDK 的写法,LangChain 的优势在于:
- 工具定义更简洁(Python 函数 vs JSON Schema)
- tool_calls 的格式是标准化的字典,不需要
json.loads()解析 ToolMessage替代了手动构造role: "tool"的字典
把流程画成一张图
用户提问
↓
模型分析 → 需要查资料吗?
↓ 是 ↓ 否
返回 tool_call 直接回答
↓
你的代码执行工具
(查数据库/调API/读文件)
↓
结果传回模型
↓
模型基于结果生成回答整个流程中,模型做了两件事:判断要不要用工具,以及基于工具结果推理出最终回答。
而中间“真正干活”的环节——执行查询、读取数据——全部是你的代码在做。
这意味着你拥有完全的控制权:你决定模型能用哪些工具、工具连接哪些数据源、返回哪些数据、以什么格式返回。数据层完全在你手里。
我们的思考
讲到这里,你可能已经意识到了一件事:Tool Use 本质上就是 Agent 与数据层之间的标准交互协议。
在后续的模块中,你会反复看到同一个模式:
- D2-D3(RAG):Agent 声明“我需要查询知识库”→ 你的代码调用 seekdb 执行混合检索 → 结果返回给 Agent → Agent 基于检索结果回答。Tool Use 是这个流程的触发机制。
- D4(Memory):Agent 声明“我需要存储/读取一条记忆”→ 你的代码调用 PowerMem → 记忆数据的存取通过 Tool Use 完成。
- D5(Skill & MCP):Agent 声明“我需要调用某个外部服务”→ 通过 MCP 协议连接外部工具 → 底层仍然是 Tool Use 在驱动。
换句话说:Tool Use 不是一个孤立的 API 特性——它是 Agent 架构的连接层。模型的推理能力和外部数据之间,就靠这一层协议打通。你在 D1 理解了这个机制,后面所有模块的代码,你都能看懂它们在做什么。
从数据的视角看,这里有一个和 PM 路径遥相呼应的观察:P1 讲“90% 的 Agent 功能失败不是模型不行,而是数据不到位”。对应到工程层面就是——Tool Use 的代码你可以写得很漂亮,但如果工具背后的数据层(知识库、记忆系统、外部数据源)没建设好,模型拿到的依然是垃圾数据,最终的回答质量不会好。
代码连接的是管道,数据才是水。管道再精良,没水也白搭。
这节课要留下的印象
如果这节课的所有内容你只记住一段话,记住这段:
Tool Use 把大模型从“只能说”变成了“能做事”——这是聊天机器人和 Agent 的分界线。模型负责判断和推理,你的代码负责执行和获取数据。后续所有模块的 Agent 能力——查知识库、存记忆、调外部服务——都建立在这个机制之上。
课后行动:跑通真正的 Tool Use 示例(重要)
我们相信,最好的学习,就是亲手实现它
1. 安装 Python
检查一下是否已经装了:
python3 --version如果能输出版本号(如 Python 3.10.x),就说明已经有了。如果没有,需要先去 python.org 下载安装。
2. 安装 langchain-openai
本期课程使用 LangChain 框架,需要安装 langchain-openai 包(它会自动安装 langchain-core 等依赖):
pip3 install langchain-openai说明:
langchain-openai是 LangChain 官方维护的 OpenAI 集成包。它兼容所有 OpenAI API 格式的服务(包括硅基流动),所以你不需要额外安装openai库。
3. 填入你的 API Key
在硅基流动注册一个账号,并获取你的 API Key,用于进行测试。
在运行代码前,需要先把每个 .py 文件中的 YOUR_API_KEY 替换成你在硅基流动获取的真实 API Key。
4. 运行本期课程中涉及到的 d1_1 ~ d1_4 的代码
python3 d1_1_base.py # 基础调用
python3 d1_2_multi_turn.py # 多轮对话
python3 d1_3_streaming.py # 流式输出
python3 d1_4_tool_use_mock.py # Tool Use(Mock 版,用假数据演示流程)5. 最后一关:跑通 Tool Use 示例
推荐先跑通 d1_4_tool_use_mock.py,理解 Tool Use 的完整流程。
然后再跑通 d1_5_tool_use_seekdb.py,体验工具背后接入真实向量数据库的效果。
在体验 Tool Use 之前,需要大家先来安装这个一个非常轻量的 Tool —— pyseekdb,用于进行测试。
安装 pyseekdb 的环境要求和具体安装步骤详见官方文档:通过 pyseekdb SDK 快速体验向量搜索。
使用 pip 安装,会自动识别默认的 Python 版本和平台。
pip install -U pyseekdb说明:pyseekdb 1.1.0+:原生支持 macOS 15 及以上,不仅限于 Linux(glibc >= 2.28)。
这里也推荐大家通过使用 AI Agent 来代替手动安装 pyseekdb。(如果您还没有使用过类 AI Agent 的产品,推荐安装 Qwen Code ,并用 Qwen Code 来安装 pyseekdb)
提示词:
根据 https://docs.seekdb.ai/seekdb/zh-CN/experience-vector-search-with-sdk 的内容,在我的电脑上安装 pyseekdb 并进行测试。完成 pyseekdb 的安装之后,就可以在 d1_5_tool_use_seekdb.py 填写你的 API Key,然后运行 Tool Use 示例了。
python3 d1_5_tool_use_seekdb.py至此,您已经亲身体验了 Tool Use,并理解了 Tool Use 的完整流程。
6. 附加题——温故知新:还记得大明湖畔的《F2:AI Agent 的完整图景》吗?
在 LangChain v1 版本中,支持了全新的 create_agent 架构。这意味着即使你使用的是相对简单的 LangChain 高阶 API,也能拥有高可靠性、记忆持久化和流式输出能力。它为标准的“模型 -> 调用工具 -> 回答” ReAct 循环,提供了最简单、最符合直觉的构建方式。
我们希望大家,能够在完成 d1_5_tool_use_seekdb.py 的基础上,继续体验 d1_6_agent.py,感受从“手动编排 Tool Use”到“一行代码创建 Agent”的跃迁。
回顾:d1_5 vs d1_6,到底省了什么?
在 d1_5 中,我们手动编排了 Tool Use 的完整流程:
调用模型 → 检查 tool_calls → 执行工具 → 把结果传回模型 → 再调用模型...这个过程需要你自己写 for 循环、拼消息、处理各种边界情况。而在 d1_6 中,create_agent 把这一切封装好了——你只需要告诉它“用哪个模型”和“有哪些工具”,它就会自动完成 F2 中讲的“推理 → 行动 → 观察”循环:
from langchain.agents import create_agent
agent = create_agent(
model=llm,
tools=[search_knowledge_base],
system_prompt="你是一个 AI 技术文档助手...",
)
result = agent.invoke({"messages": [("user", "你的问题")]})Agent 会自主决定:要不要查知识库?查完够不够?需要换个关键词再查一次吗?——这就是 F2 中说的:
“Agent 不是一次性生成答案,而是在‘思考-行动-观察’的循环中逐步完成任务。”
关于 API 兼容性的说明
create_agent 要求底层 API 完全兼容 OpenAI 的 tool calling 消息格式(role: "tool" + assistant.tool_calls)。d1_1 到 d1_5 使用的硅基流动 API 在这方面尚未完全兼容,因此 d1_6 切换到了阿里云百炼(通义千问)API:
from langchain.chat_models import init_chat_model
llm = init_chat_model(
"qwen-plus",
model_provider="openai",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="YOUR_API_KEY", # 在阿里云百炼平台获取
)百炼 API Key 的获取方式:前往阿里云百炼平台注册,在「API-KEY 管理」中创建即可,新用户有免费额度。
除百炼外,OpenAI 官方、DeepSeek 官方(https://api.deepseek.com/v1)等 API 也完全兼容,可以直接使用。
运行 d1_6
安装 LangChain v1 的 Agent 依赖(如果之前没装过):
pip3 install -U langchain langgraph填入你的百炼 API Key 后,运行:
python3 d1_6_agent.py你会看到 Agent 针对每个问题,自动调用知识库工具、检索文档、生成回答的完整过程。
7. 总结
这期课程里的这三个步骤,是后续所有模块的基础。如果你在这里卡住了,后面的 RAG、Memory、MCP 模块都会很吃力。确保这三步跑通了,再继续下一个模块。
- 定义一个工具——用
@tool装饰器定义一个 Python 函数(函数名、docstring、参数类型注解) - 让模型调用它——用
llm.bind_tools()绑定工具,发送一条需要使用工具的消息,确认模型返回的是tool_calls而不是文本回答 - 处理返回结果——执行工具调用,用
ToolMessage把结果传回模型,拿到最终回答
一个调试小技巧:如果模型没有调用工具而是直接回答了,八成是你的工具 docstring 写得不够清晰——模型不知道什么时候该用它。试着把描述写得更具体,明确告诉模型“在什么情况下使用这个工具”。
延伸阅读
如果你对本期提到的概念想做进一步了解,以下是一些推荐资源:
- LangChain ChatOpenAI 文档:ChatOpenAI Integration,LangChain 官方的 ChatOpenAI 集成文档,包含工具调用、流式输出等完整示例
- LangChain Tool Calling 指南:Tool Calling with LangChain,LangChain 官方博客,详细介绍了
bind_tools、tool_calls、@tool装饰器的标准用法 - OpenAI Function Calling 文档:Function Calling Guide,了解底层的工具调用协议,有助于理解 LangChain 在背后做了什么封装
下期预告:
道篇:P2 · Agentic RAG 产品设计——会为大家介绍 AI 产品设计中的哪些决策会直接影响用户体验;以及 AI 产品数据层中最常见的检索陷阱。大家可以获得一个可以立即用于日常工作的归因框架——下次有人说“AI 答得不好”,你会知道该从哪里查起;以及了解 AI 数据层检索问题的行业标准方案。
术篇:D2 · 知识库构建与混合检索——Tool Use 让 Agent 能“查知识库”,但知识库本身怎么建?数据怎么切分、怎么向量化、怎么检索?我们会用 seekdb 从零构建一个可用的知识库,并实际验证:数据质量的不同,如何直接影响 Agent 回答的质量。