Easy Data x AI 课程 · 道篇 · 第二期
本期是课程最重要的模块之一,会为大家介绍 AI 产品设计中的哪些决策会直接影响用户体验;以及 RAG 数据层中最常见的检索陷阱。
通过本期课程,你将获得一个可以立即用于日常工作的归因框架——下次有人说“AI 答得不好”,你会知道该从哪里查起;以及了解 RAG 数据层检索问题的行业标准方案。
前文回顾:用户说“AI 没能解决我的问题”,到底是谁的错?
在公共基础篇 F1 中,我们确立了一个核心判断,大模型有三个局限——幻觉、知识截止、个性化盲区。这些局限在本质上是同一个问题:它只有训练数据,没有你的数据。
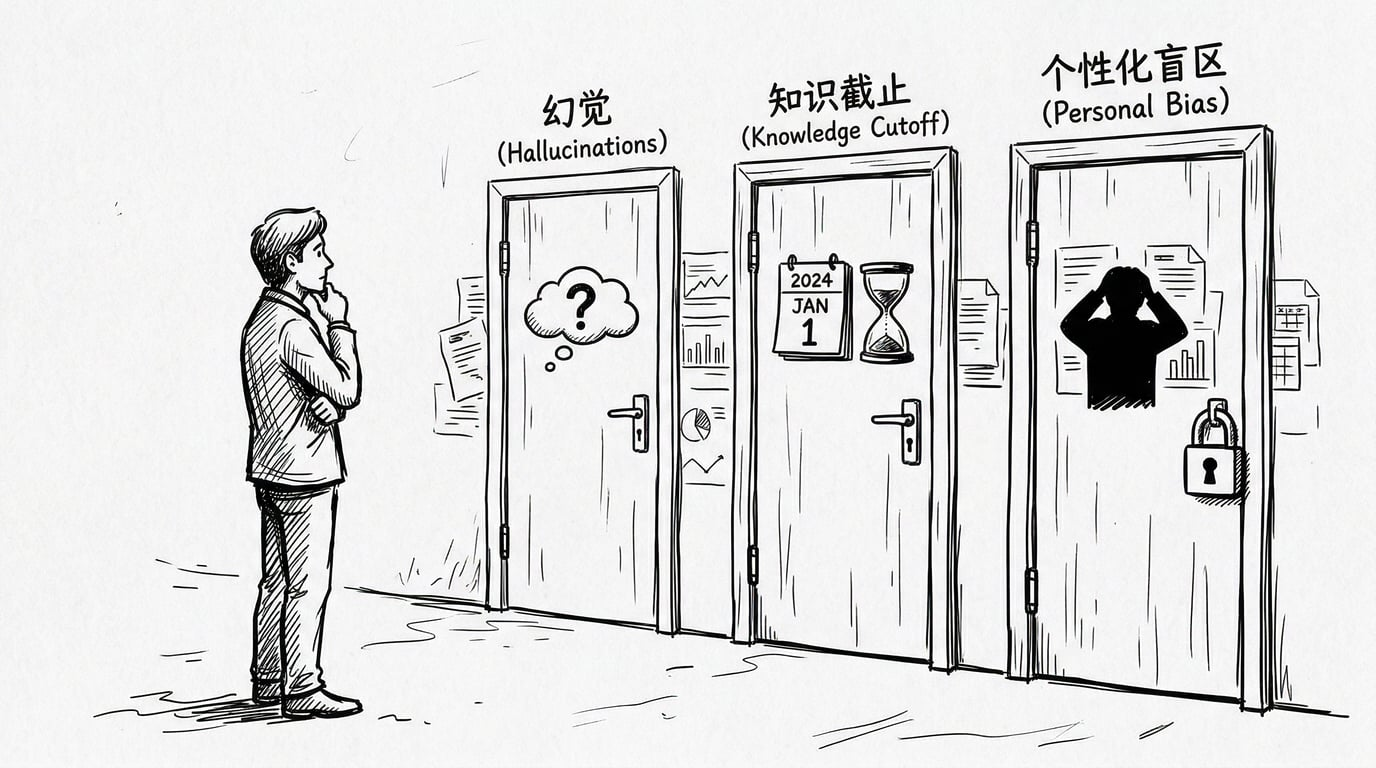
在 F2 中,我们画了一张地图,看到 Agent 的每一项能力拆到底,都是数据的存储与检索。
我们针对这个问题,给出过一个判断:不是“AI 答错了”,而是 AI 没拿到正确的数据。
今天这节课,我们要把这个判断从直觉变成方法论。我会给你一个具体的归因框架和一棵决策树——下次再遇到“AI 答得不好”,你不需要猜,按流程走就能定位到问题在哪一层,该用什么解法。
第一部分:先聊聊对 RAG 的常见误解
很多人一提到 RAG,脑子里默认出现的是“向量数据库 + 相似度搜索 + LLM 回答”。但这其实是 RAG 的一种早期实现,不是 RAG 的定义本身。
RAG 全称是 Retrieval-Augmented Generation,重点在第一个词:Retrieval,检索。
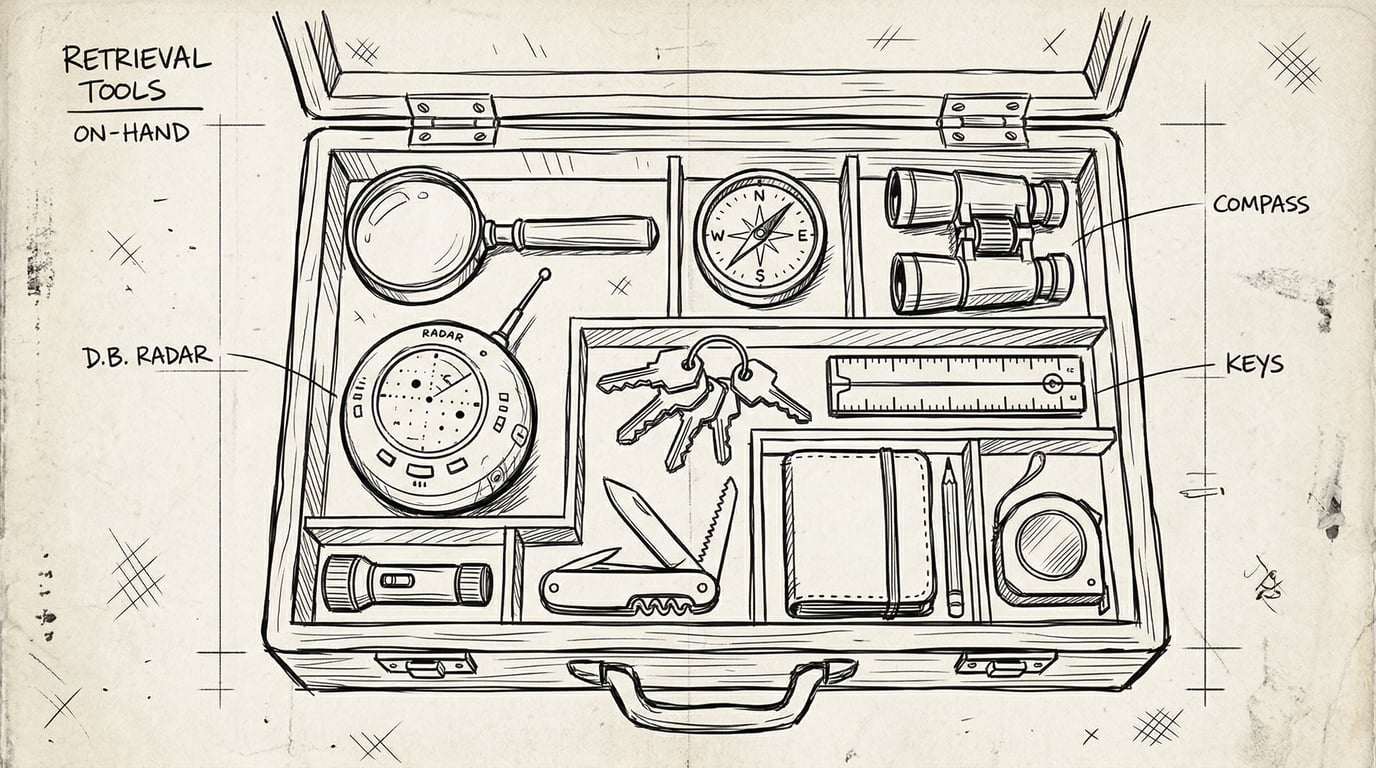
这里的“检索”不是特指向量检索,而是所有能把有用信息取回给模型的手段,例如:
- 全文 / 关键词检索:适合错误码、版本号、产品名、专有名词
- 向量语义检索:适合口语化提问、同义表达、模糊需求
- 标量 / 元数据过滤:适合按租户、时间、产品线、权限、文档类型做范围筛选
- 图谱 / 关系跳转:适合多跳关系问题,例如“这个客户对应哪个行业方案,再对应哪些成功案例”
- API 工具调用:适合查实时搜索引擎结果等
所以,今天讲 RAG,不能把它等同于“向量检索”。只要系统在生成前,先去外部世界取信息给模型,广义上都属于 RAG。
最早很多 RAG 系统默认就是“一次向量搜索 + 一次生成”;而现在,RAG 更像一个工具箱:可以搜知识库、搜全文、查数据库、调 API、跑站内搜索。
这一定义一旦讲清,后面的很多判断就顺了:
- 问题不一定出在模型,也可能出在“取信息”的路径设计
- 优化 RAG,不等于只优化 embedding 或向量库
- 一个好的 Agent,不是“更会答”,而是“更会找”
站在 PM 视角,你真正要负责的,是这套“找信息”的系统边界:找什么、去哪里找、何时找、怎么合并、能给谁看。
先说清楚:向量搜索当然重要,它解决的是“语义相近”这件事。系统会把文本转化成向量,再根据向量之间的距离,判断两段内容在意思上是否接近。这个方法在大多数情况下效果很好。但它有一个结构性的弱点:它理解“语义”,但不理解“精确”。
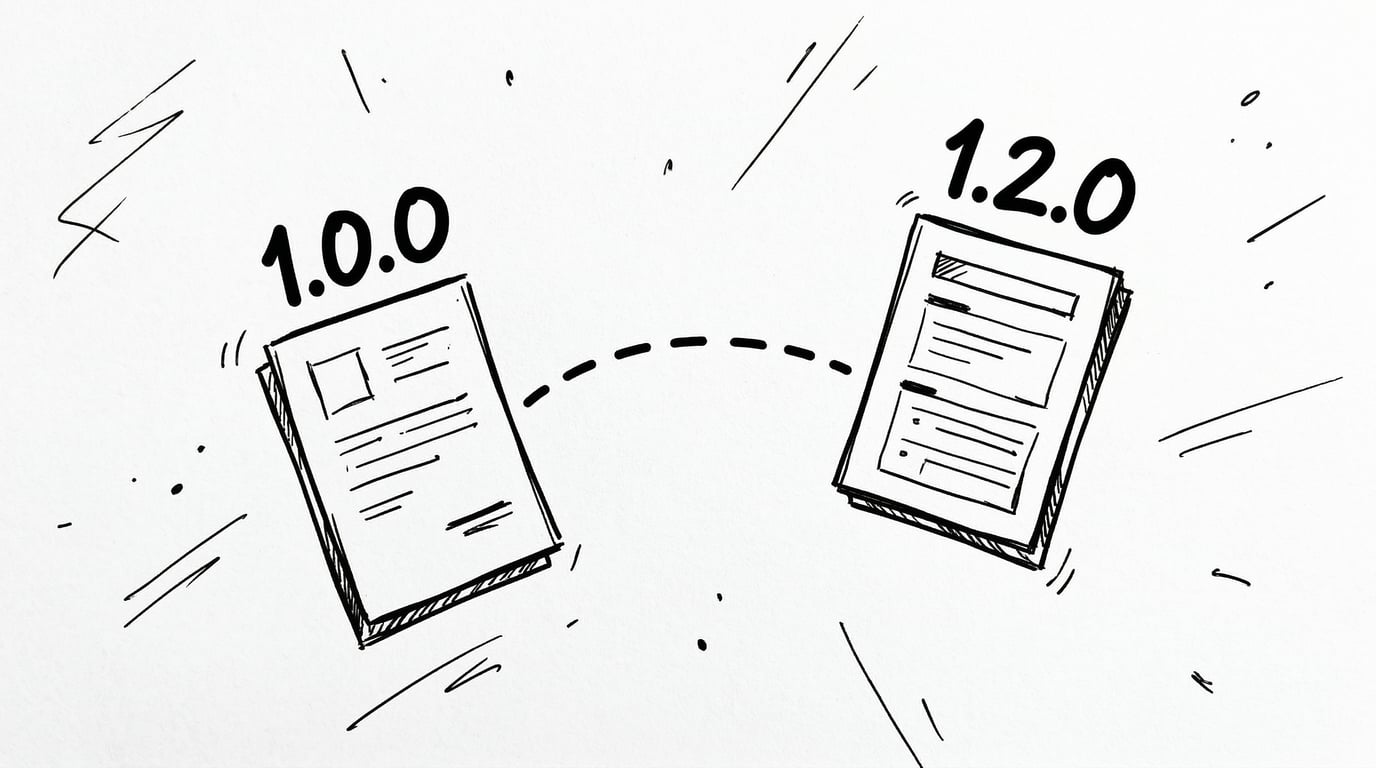
拿一个我在自己的生产环境里,遇到过的真实问题来举例,例如:用户搜索“seekdb 1.2.0 版本的兼容性”。
曾经 OceanBase 社区里的第一个 RAG 产品——论坛小助手,就只有纯向量搜索的能力,它就真的会去这么理解用户的问题:“用户想了解 seekdb 某个版本的兼容性问题。”
然后它去知识库里找“意思最相近”的内容。结果呢?它很可能返回了 seekdb 1.0.0 版本的兼容性文档——因为在向量空间里,“seekdb 1.2.0 的兼容性”和“seekdb 1.0.0 的兼容性”确实“语义非常相近”,它们都在讨论“seekdb 这款产品的兼容性”。
但用户需要的是 1.2.0,不是 1.0.0,这两个版本的兼容性信息可能完全不同,论坛小助手的效果没有达到预期,用户纷纷吐槽。
这个问题让我们快速意识到支持向量搜索还不够,“混合搜索”也是必不可少的能力(所以,我们很快就在之后 OceanBase/seekdb 版本中支持了“混合搜索”,并不断把混合搜索的性能优化到了业界最领先的水平)。
上述这个问题,在企业场景中十分常见,因为企业知识库里充满了:
- 产品型号:OceanBase 4.4.1、seekdb 1.2.0
- 版本号:v4.2.1-LTS(Long-Term Support)、v4.4.2-CE(Community Edition)
- 错误代码:ERROR 4012、ERROR 4016
- 精确数值:128GB、256GB
这些内容的向量表示都很“相近”(它们都是“产品技术信息”),但精确匹配至关重要。
所以问题不在于“向量检索没用”,而在于:它只是 Retrieval 里的其中一路,不应该独占整个 R。
我们后续在开发产品的过程中,也反复验证了这样一个判断:如果你把 RAG 默认等价于向量搜索,在生产场景里,检索效果不符合用户预期,几乎是必然的。
第二部分:传统 RAG 和 Agentic RAG,区别在哪儿?
如果用一句话概括:
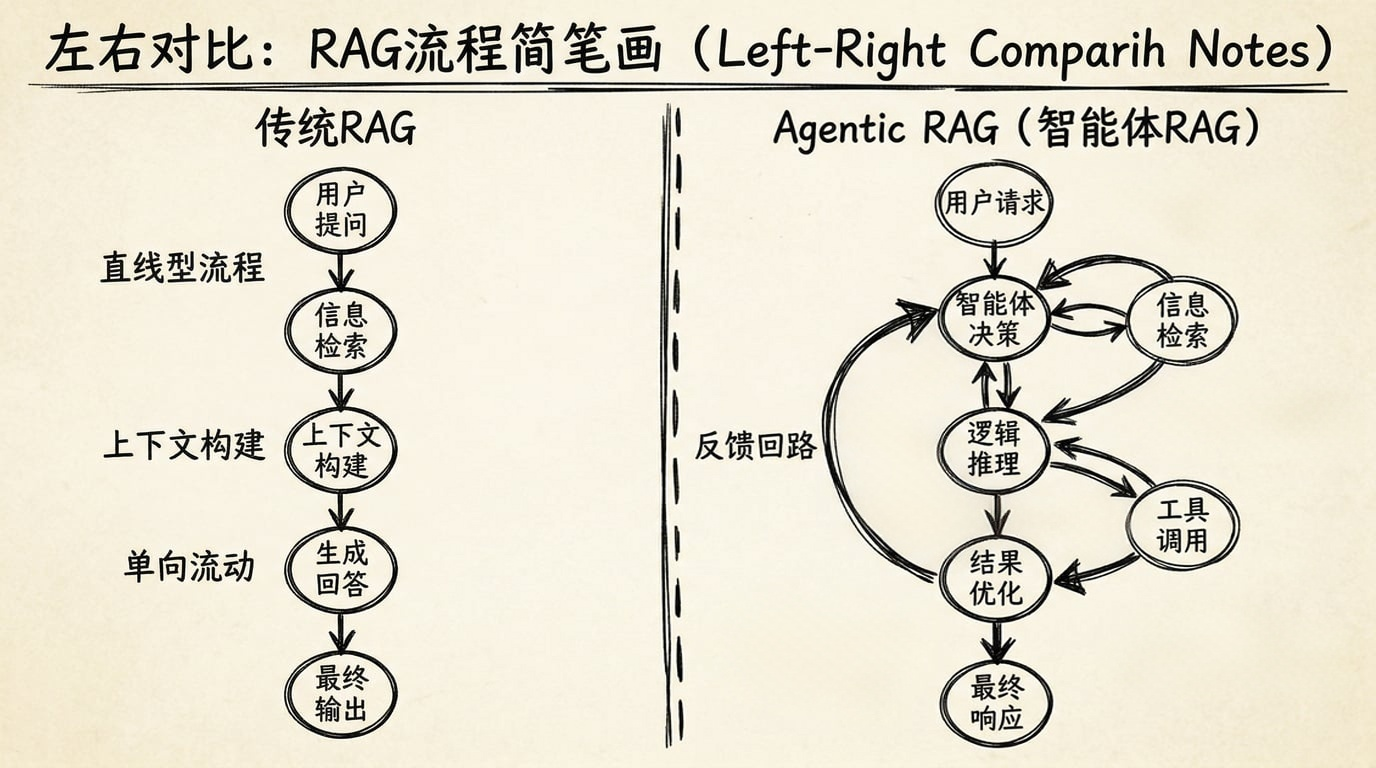
- 传统 RAG:流程大多是预先设计好的,一般是无环的
- Agentic RAG:流程里开始出现闭环,系统可以自主决定下一步怎么走
传统 RAG:通常是无环流程,可以复杂,但大多是写死的
很多人一提传统 RAG,就把它想成:
用户提问 → 改写 query → 检索一次 → 取 TopK → 拼进 Prompt → 模型回答
但这其实只是最朴素的一种写法,不代表传统 RAG 只有这么简单。
早期很多成熟的 RAG 系统,流程已经可以相当复杂了。
它们会有:
- query 改写
- query 路由
- 多路召回
- 重排
- 上下文压缩
- 引用生成
- 答案后处理
也就是说,传统 RAG 不一定简单,但它通常还是一个预先设计好的无环流程。
你可以把它理解成一张流程图,允许有分支、有路由、有并行节点,但大多数时候仍然是一个 有向无环图(DAG):
- 问题进来
- 按既定规则走若干节点
- 最后产出答案
- 一旦走完,本轮结束
所以,传统 RAG 的核心不在于“节点少”,而在于:节点之间的关系,大多是预先写死的;系统通常不会自己决定回到上一步,再来一轮。
这也是为什么你会看到早期 RAG 其实已经有很丰富的流程设计。只是那个阶段的优化重点,更多还是在每个节点本身做文章,而不是让系统去自主改写整条路径。
Agentic RAG:关键不是更复杂,而是开始有循环
我们在前面的课程中曾经讲过 Agent 的本质就是循环迭代的 ReAct 模式:
感知 → 推理 → 行动 → 感知 → 推理 → 行动 → ... → 循环。
Agentic RAG 的关键变化,不是“节点更多了”,而是:流程里开始出现闭环,系统可以根据中间结果,自主决定下一步,也可以反复对某个节点做处理。
也就是说,它不再只是:沿着一张预先设计好的 DAG 往下走。而开始具备:
- 结果不够好,就回去再搜一次
- 搜索方式不对,就换一路再试
- 证据不够,就继续补充
- 某个环节可以封装成工具,按需调用
- 整条路径不是提前写死,而是边运行边决定
所以,Agentic RAG 的本质是把“如何检索、是否重试、是否补搜、是否调用工具”这些问题,交给系统在运行时自己判断。
Agent 会主动判断:
- 要不要检索:这个问题靠模型常识就能答,还是必须查外部资料?
- 先检索哪一路:先查 FAQ、文档、数据库、站内搜索,还是直接调用某个工具?
- 一次够不够:第一次结果不理想,要不要改写 query、换路由、补搜第二轮?
- 要不要多跳:当前答案是否依赖前一步结果,例如先找产品版本,再查该版本的兼容性说明?
- 怎么合并证据:来自不同来源的结果,如何重排、去重、归因,再交给模型生成?
这就是两者在结构上的核心差异:
- 传统 RAG:通常是无环的,流程走完就结束
- Agentic RAG:可以有环,可以在某一步停下来、回退、重试、补搜、改路由
而这对应到用户体验上,就是:
- 传统 RAG 像“按既定流程查了一遍”
- Agentic RAG 像“主动在替你反复找、反复核对、反复修正”
用户觉得系统“更聪明”,往往不是因为模型突然更强了,而是因为流程开始可以自我调整了。
混合搜索 —— 传统 RAG / Agentic RAG 都强依赖的重要能力
因为真实世界的问题,本来就不是单一路径能解决的。
举个例子,用户问:
seekdb 1.2.0 在金融客户环境里的兼容性要求是什么?如果已经部署 1.0.0,升级前要注意什么?
这个问题至少混合了四类检索需求:
- 语义理解:用户可能不会用文档里的标准表述,需要语义召回
- 精确匹配:
seekdb 1.2.0、1.0.0这种版本号必须字面命中 - 范围过滤:需要限定行业、版本、文档类型、发布时间
- 多跳整合:先找兼容性要求,再找升级注意事项,最后合并成一个回答
如果你只用单次向量检索,往往只能解决第一类,后面三类都很容易出问题。
这件事跟你是不是 Agentic RAG 没关系,只要你在做生产级 RAG,就一定都会遇到。
所以,混合搜索不是“高级玩法”,也不是“Agent 时代才出现的东西”,而是因为问题天然有多种信息需求。常见组合包括:
- 向量检索:解决“怎么表达都能找到”
- 全文检索:解决“专有名词和精确信息必须找准”
- 标量检索:解决“只在正确范围内找”
- API 工具调用:解决“实时状态和结构化数据要直接查”
从这个角度看:Agentic RAG 和传统 RAG一样,都需要混合搜索,但它会把这些搜索方式当成可动态调用的能力。
第三部分:一个完整的 RAG,基础流程通常是怎么设计的
很多人谈 RAG,只盯着“搜索”那一步。其实一个能上线、能持续优化的 RAG 系统,至少要有这样一条完整链路:
数据准备(indexing) → 问题理解与改写(query analysis / transformation) → 搜索召回(retrieval) → 融合重排(fusion / reranking) → 回答生成(generation) → 评估反馈(evaluation)
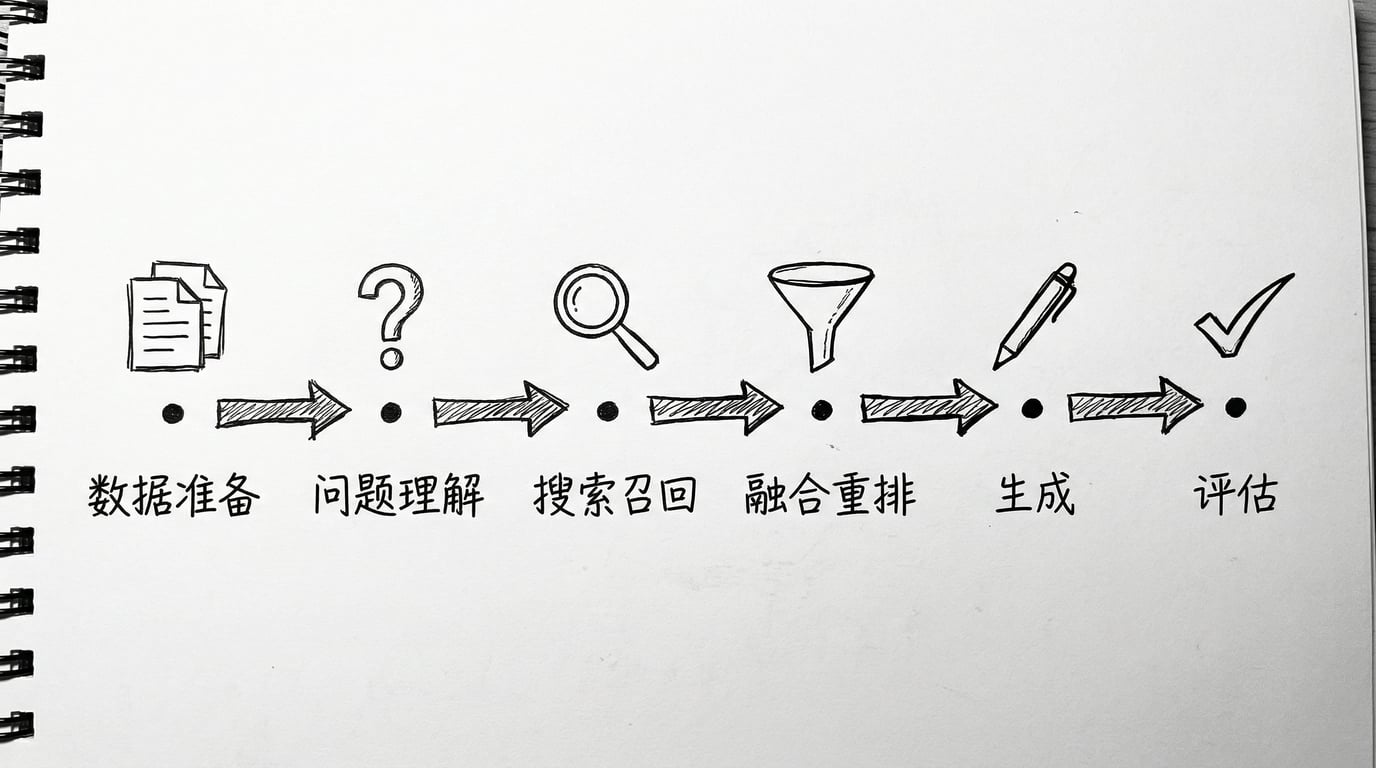
这六步里,前面三步决定“能不能找对”,后面三步决定“能不能答对”。
1. 数据准备
这是最容易被低估、但最影响最终效果的一步。
数据准备不是“把文档丢进向量库”这么简单,而是要回答几个问题:
- 怎么加载(load):产品文档、FAQ、工单、API 文档、内部 SOP、运营规则、数据库表、外部网页,哪些要纳入系统
- 怎么解析(parse):PDF、HTML、Markdown、表格、截图转录后的文本,如何转成可处理结构
- 怎么清洗(clean):去重、去噪、去过期、去模板垃圾,保留真正有信息密度的内容
- 怎么切分(split):按段落、章节、问答对、语义块还是结构块切分内容块(chunk)
- 怎么增强(enrich):补标题、章节、别名、术语、版本号、权限、时间等元数据
- 怎么建索引(embed / index):建立向量索引、全文索引、过滤索引,让内容真正变成“可被搜索”
- 怎么更新(refresh):全量重建、增量同步、定时刷新、事件触发
这一层为什么重要?因为后面的混合搜索,很大程度上依赖这些准备工作。
- 没有清晰的标题和结构,语义搜索的召回会变差
- 没有版本号、产品线、权限标签,过滤搜索就做不准
- 没有别名、术语归一和关键词补充,全文搜索就容易漏
- 内容块(chunk)切得太碎,会丢上下文;切得太大,会引入噪音,后续重排和生成都会受影响
换句话说:数据准备,决定了你后面到底有没有资格谈“高质量检索”。
2. 改写 & 路由
用户问题进来后,系统通常不会直接原样去搜,而是会先做一层理解:
- 问题分析(query analysis):识别问题意图,是问概念、步骤、对比、状态,还是实时数据
- 实体抽取(entity extraction):提取产品名、版本号、错误码、时间范围、客户类型等关键对象
- 问题改写(query rewrite):把口语问法转成更适合搜索的表达
- 问题扩展(query expansion):补别名、补同义表达、补隐藏条件
- 问题拆解(query decomposition):把复杂问题拆成多个子问题分别处理
- 假设文档生成(HyDE):先生成一段“假想答案 / 假想文档”,再用它增强语义搜索
- 回退提问(step-back prompting):先把具体问题抽象成更高层问题,再反过来帮助召回
- 路径路由(routing):判断应该走全文、向量、过滤、SQL,还是混合调用
这一层本质上是在做一件事:把“用户语言”翻译成“系统更容易找对信息的语言和路径”。
3. 搜索召回
召回阶段的目标不是“直接给出答案”,而是尽可能别漏掉可能有用的证据。
典型做法包括:
- 向量召回(vector retrieval):找语义相关内容
- 全文召回(full-text retrieval):找精确匹配内容
- 标量召回(scalar retrieval):限制产品、版本、权限、时间范围
- 结构化查询(structured retrieval):走 SQL、接口或业务系统,拿结构化或实时信息
- 多表示召回(multi-representation retrieval):先按摘要找、再回到原文;或先按子块找、再回到父文档
- 父子检索(parent-child retrieval):先用小块提高命中率,再回到更大上下文保留完整性
这一步更偏“广撒网”,宁可稍微多一些候选,也不能一开始就把关键证据漏掉。
4. 融合 & 重排
不同来源的结果回来后,不能直接一股脑塞给模型,还要做:
- 结果融合(fusion):把向量、全文、过滤、工具查询返回的结果合在一起
- 去重(deduplication):去掉重复内容和高度相似内容
- 合并相似内容块(chunk merge):把被拆散的证据重新拼回有意义的上下文
- 重排序(reranking):按真实相关性重新排序,而不只是按初始召回分数
- 融合排序(RRF 等):把多路检索结果做稳定融合,避免单一路径偏置
- 可信度加权:把来源权威性、发布时间、权限范围一起纳入排序
- 上下文压缩(compression):只保留真正有用的信息,控制后续上下文长度
很多系统效果差,不是“没搜到”,而是搜到了但排序出了问题。
5. 上下文组织与生成
把最关键的证据交给模型时,还要解决两个问题:
- 上下文组装(prompt assembly):按主题分组、按时间排序、按问题子任务拆分
- 证据引用:要求回答给出来源,让用户知道每个结论来自哪里
- 约束生成:信息不足时明确说不知道,避免模型硬编
- 结构化输出:在需要时输出步骤、表格、JSON、结论摘要
- 后处理(post-processing):补格式、补引用、补安全规则、补业务规则
这一步决定的是:模型能不能把“找到的资料”真正转成“可用的回答”。
6. 评估与反馈闭环
最后,RAG 不是答完就结束。上线后还需要追踪:
- 过程评估:哪些问题经常搜不到,哪些问题经常搜偏,哪些路径总是失败
- 节点评估:改写是否有效、路由是否正确、重排是否稳定、压缩是否过度
- 结果评估:哪些回答被用户点踩、追问或纠错
- 来源分析:哪些来源高频命中,哪些来源长期无效,哪些来源噪音很大
- 闭环优化:根据这些反馈回去补数据、改切分、补标签、调路由、换重排策略
这些反馈会反过来指导你补数据、改内容块(chunk)、补标签、调路由、改重排。
所以一个完整的 RAG,不是“检索 + 生成”四个字,而是一条能持续调优的产品链路。这条链路里,任何一环做差了,最后都会表现成一句话:“AI 没能解决我的问题。”
EX1. 标准 RAG 流程上的常见增强节点
这些内容,讲的是标准 RAG 流程里常见会加哪些节点:
1. Naive RAG
最基础的形态:用户提问 → 搜一次 → 取 TopK → 拼 Prompt → 回答。
优点是简单、便宜、容易落地;缺点是对 query 质量和单次召回质量非常敏感。
2. Query Rewrite RAG
在搜索前,先让模型把用户问题改写成更适合搜索的 query。
适合用户表述口语化、上下文不完整、问题很长但搜索关键词很少的场景。
这个节点加在流程最前面,解决的是“用户会问,但系统不会搜”的问题。
3. CRAG(Corrective RAG)
CRAG 的核心思想是:在检索之后、生成之前,先判断这批证据值不值得用。
系统会引入轻量级评估器判断结果质量。如果结果不够好,就触发纠错动作,例如重新搜索、引入外部搜索源、补充第二轮证据,再决定是否进入生成。
CRAG 就像给 RAG 增加了一个“查稿编辑”,发现资料不对劲,就立刻要求重新查资料,从而提升系统鲁棒性。
CRAG 的工作流程如下:
Query → 检索文档 → 评估器打分 → 判断文档相关性
↓
┌───────────────┼───────────────┐
Correct Ambiguous Incorrect
(直接使用) (补充搜索) (网络搜索替代)
↓ ↓ ↓
生成答案 合并后生成 重新生成答案4. Self-RAG
Self-RAG 的核心思想是:把“要不要检索”“检索结果够不够”“答案有没有证据支撑”这些判断,部分内化到模型自己身上。
系统会把检索、判断、生成、校验这些动作部分内化到模型决策里,让模型不仅回答问题,还参与“是否需要更多证据”的判断。
Self-RAG 的工作流程如下:
Query
↓
[Retrieve?] → 模型判断是否需要检索
├── 不需要 → 直接生成
└── 需要 → 检索文档
↓
[IsRel?] 文档是否相关?
↓
生成候选答案
↓
[IsSup?] 答案是否有文档支撑?
↓
[IsUse?] 答案是否有用?
↓
输出最终答案(选择得分最高的)你可以把它理解成:在流程里加入“自我检查”。
这些增强节点放在一起看,会更容易理解一件事:
RAG 的演进,不只是“换一个更强的检索器”,而是在标准流程的不同位置上,不断插入新的判断节点、修正节点和反馈节点。
EX2. 评估不能只看主观感觉:认识一下 RAGAS
评估在 RAG 流程中十分重要。如果没有这一层,你就不知道系统到底是“搜漏了”、“搜偏了”、“排错了”、“答编了”,还是“答得不贴题”。
RAGAS 的核心价值就在这里:为标准 RAG 流程里的中间过程和最终输出,建立了一组有参照系的评估方式。
RAGAS 有四类核心评估指标,正好可以和上面的 RAG 流程一一对应起来:
- 上下文召回率(Context Recall):搜索召回阶段 —— 该召回的证据,有没有被召回来
- 上下文精确度(Context Precision):融合重排阶段 —— 召回的上下文里,有多少是真正相关的,而不是噪音
- 忠实度(Faithfulness):生成阶段 —— 最终回答是否忠于给定上下文,有没有编造
- 答案相关性(Answer Relevancy):回答用户阶段 —— 最终回答是否真正回答了用户问题,而不是答非所问
这四个指标的价值在于:它们能帮你把“AI 怎么感觉不太行”拆成更具体的问题:
上下文召回率低:通常是数据覆盖、数据准备、query 改写或搜索策略有问题上下文精确度低:通常是混入了太多噪音,重排或过滤做得不够忠实度低:通常是模型幻觉、Prompt 约束不足、引用设计不够答案相关性低:通常是问题理解错了,或者虽然检索到了证据,但回答没有围绕用户意图组织
EX3. 从 RAG,到 Agentic RAG
讲到这里,其实可以再往前走一步:Agentic RAG 不是把 RAG 推倒重来,而是在原有流程上,逐步增加“判断”和“编排”能力。
传统 RAG 的典型路径是:
用户提问 → 搜一次 → 取 TopK → 拼 Prompt → 回答
而 Agentic RAG 的升级,本质上就是围绕这些默认假设,一步一步加能力:
- 先加 query 改写:让系统更会搜
- 再加混合搜索:让系统能自适应地选择最优的搜索方式,并对不同搜索方式召回的结果进行融合重排
- 再加结果判别和重试:让系统知道“这次搜得不够好,需要补搜”
- 再加多轮编排:让系统可以先过滤、再搜索、再合并,而不是一步到位
- 最后再加工具调用和外部数据源:把“知识库问答”升级成“面向任务找信息”
所以,传统 RAG 到 Agentic RAG 之间,并不是一道鸿沟,而更像是一条连续的演进路径:
传统 RAG:固定流水线增强 RAG:在流水线上加入改写、重排、纠错、补搜Agentic RAG:让系统能根据问题动态决定走哪条路径、走几轮、是否调用工具
这也是为什么很多团队真正的升级方式,不是“今天上普通 RAG,明天直接变成 Agent”,而是:
- 先把标准 RAG 跑通
- 再把搜索质量做好
- 然后把流程节点补齐
- 最后才把这些节点交给 Agent 去编排
这样升级的好处是:前面的每一步都不是浪费,都会成为后面 Agentic RAG 的基础设施和能力积累。
也正因为如此,后面要讲的“混合搜索”才这么关键。因为如果底层只支持单一路径、单一搜索方式,那你前面即使想加判断、补搜、改写、分支,最后也很难真正把流程升级成 Agentic RAG。
更进一步说,数据库在这里的价值,不只是“支持混合搜索”这四个字,而是把这部分复杂度尽量内置掉:
- 开发者不用自己拼多套系统
- 不用自己对齐不同搜索方式的结果
- 不用自己在应用层手搓大量融合逻辑
这样,外部开发者的认知负担和操作难度就会明显下降,团队才能把精力更多放在 RAG 流程本身,而不是底层胶水工程上。
第四部分:混合搜索,在 RAG 流程里的重要性
讲完流程之后,再来看一个经常被低估的基础设施问题:为什么混合搜索数据库会在今天的 RAG 里变得越来越重要?
原因很简单:不管是传统 RAG 还是 Agentic RAG,只要你在做生产级 RAG,混合搜索几乎都会成为基础能力。
而当系统进一步从无环流程升级到带闭环的 Agentic workflow 之后,底层存储和搜索引擎就更不再只是一个存文档的地方了,它开始直接参与整条流程的质量和成本。
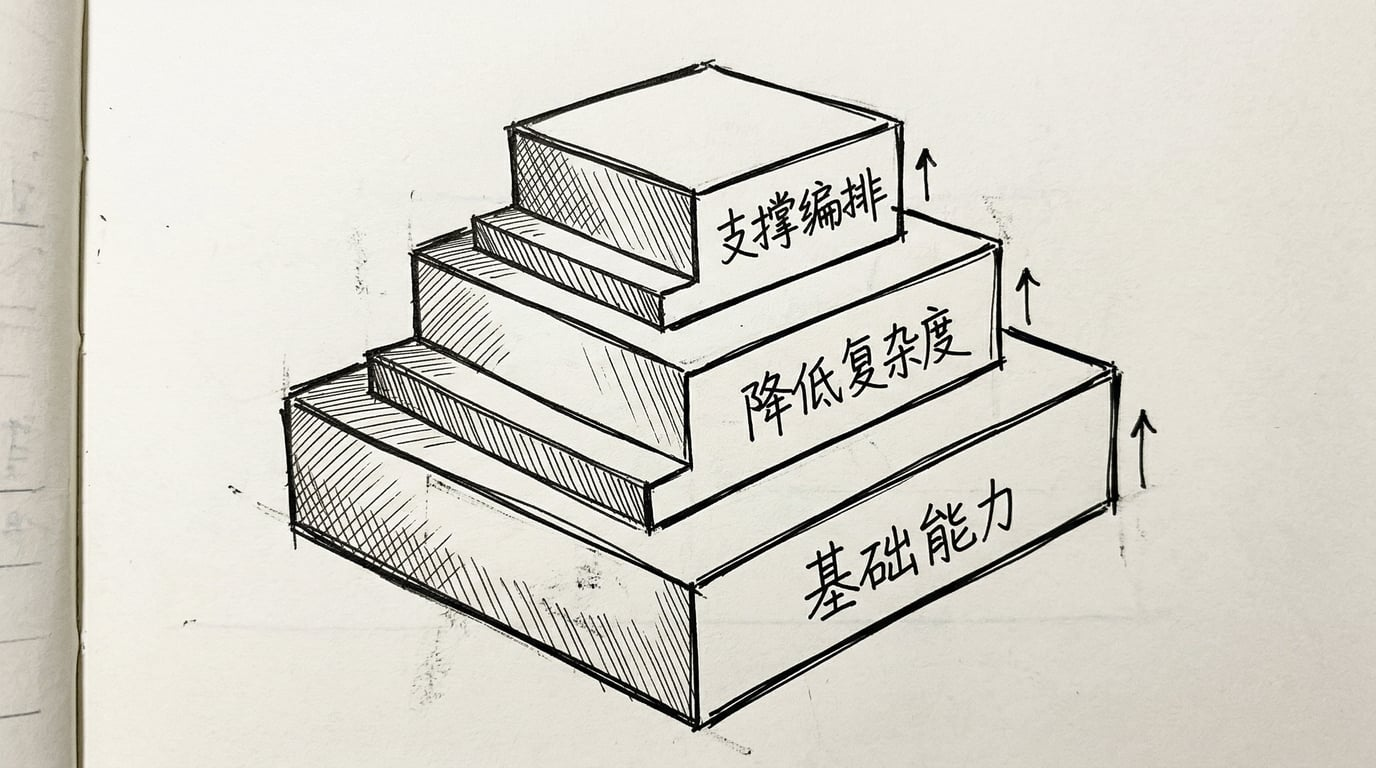
混合搜索在 RAG 流程里的作用,有三层
第一层:同时服务传统 RAG 和 Agentic RAG。
在一套底层能力里同时支持:
- 向量语义搜索
- 关键词 / 全文搜索
- 标量过滤
这样 query 进来后,系统才有可能根据问题类型去选择更合适的搜索方式,而不是被迫“所有问题都先向量搜一下再说”。
对传统 RAG 来说,这是把预设流程做对;对 Agentic RAG 来说,这是给动态决策提供可调用的基础能力。
第二层:把复杂度内置,降低开发者负担。
如果底层不支持混合搜索,团队通常就要自己拼多套系统:
- 向量库负责语义搜索
- 搜索引擎负责全文搜索
- 关系库或缓存系统负责过滤和结构化查询
- 应用层再自己做合并、去重、打分、重排
这会直接带来几个问题:系统更复杂,维护成本高;工程链路更长,延迟高;不同系统之间的分值和排序逻辑很难天然对齐,结果更不稳定。
而如果这些能力能在数据库层被内置,外部开发者就不需要自己理解和手搓太多底层细节。
第三层:支撑 Agentic RAG 的闭环编排。
一旦进入 Agentic RAG,系统会频繁做这些动作:
- 改写 query 再搜一次
- 先全文搜,再向量搜
- 先过滤范围,再做语义匹配
- 多路结果合并后再二次排序
如果底层数据库原生支持这些能力,Agent 的“多步找信息”才有现实可行性;否则 Agent 的每一次“决策”,最后都会变成工程系统巨大的额外负担。
总结
是否在 AI 系统中引入“混合搜索”,会直接影响:
- 搜索效果上限
- 系统开发/运维复杂度
- 响应延迟
- 成本结构
- 后续是否能从传统 RAG 顺利升级到 Agentic RAG
所以大家至少要理解一件事:混合搜索数据库的价值,不只是“搜得更准一点”,而是它决定了你的 RAG 能不能自然演进成可编排、可评估、可持续优化的 AI 系统。
seekdb 是 AI 原生混合搜索数据库,在一个引擎中统一向量、文本、结构化与半结构化数据,支持混合搜索与数据库内 AI 工作流。有着极简的 API 设计,让用户可以专注于构建 AI 应用,欢迎大家了解并试用。
第五部分:三层归因框架——“AI 答错了”的正确诊断方法
现在,我们进入这节课最重要的部分。
当用户反馈“AI 答得不对”时,问题可能出在三个完全不同的层面。把问题归到错误的层面,就会用错误的方法去解决——就像医生误诊一样,误诊不仅浪费治疗时间和金钱,还可能让真正的病因继续恶化。
医生误诊的类比
想象你去看医生,说“我头疼”。
一个草率的医生会直接开止疼药——对症处理,头不疼了就行。但如果你的头疼是因为高血压引起的,止疼药治标不治本,高血压继续恶化,迟早出大问题。
一个好医生会先做检查:血压正常吗?有没有颈椎问题?是不是睡眠不足?最近压力大不大?——先找到根因,再给对应的治疗方案。
“AI 答得不好”就像“头疼”——它是一个症状,不是一个诊断。你需要找到症状背后的根因,才能给出正确的解法。
三层归因框架
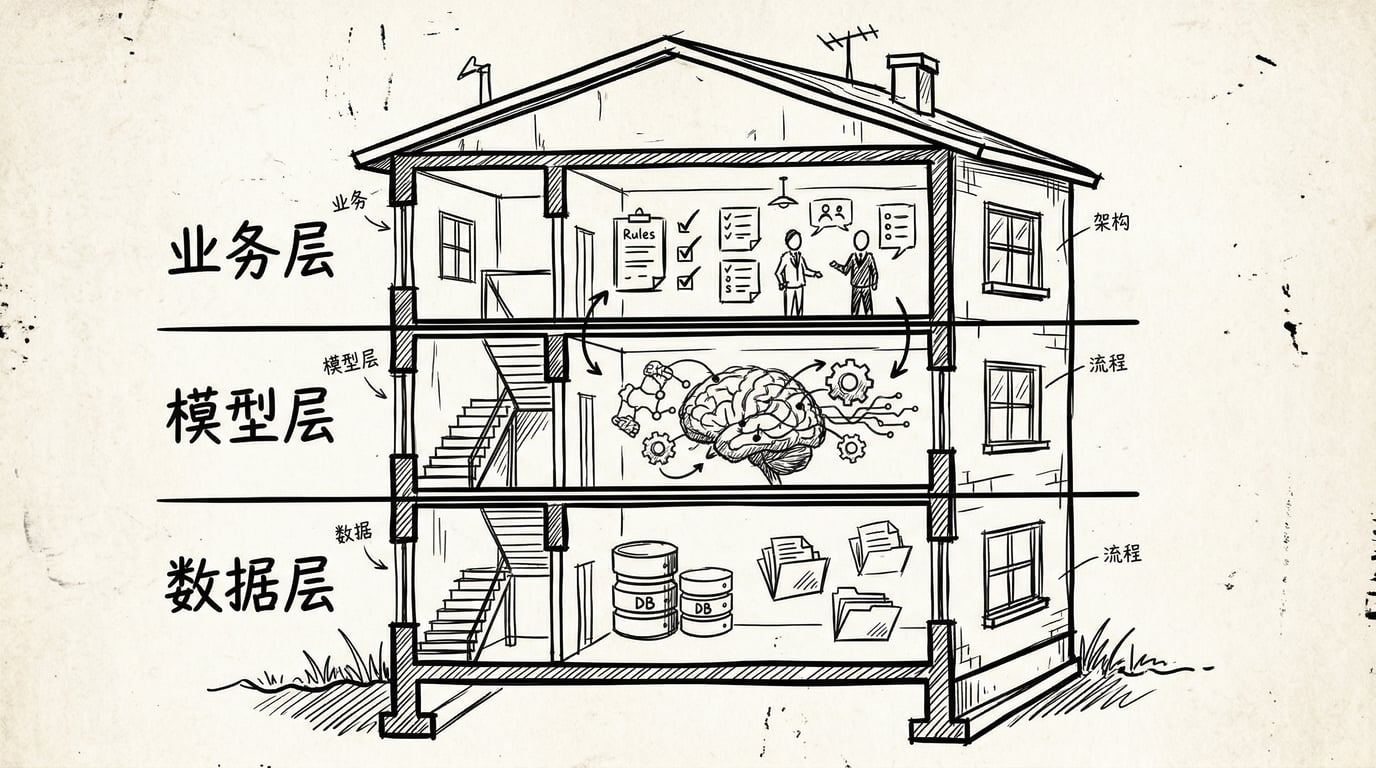
我们把“AI 答得不好”的根因分为三层: 第一层:数据层问题
数据层问题有两种表现:
表现 A:检索不到。 用户问的问题,知识库里压根没有对应的内容,或者内容虽然存在,但因为没有被清洗、切好、打标、同步,实际上“不可检索”。Agent 搜了一圈,什么都没找到(或者找到的内容完全不相关),只能基于模型自身的知识来回答——而我们在 F1 中学过,模型自身的知识很可能是过时的、不完整的,甚至是编造的。
- 根因:内容覆盖或数据准备问题
- 解法:补充知识库,或重做数据准备。把缺失内容补进去,把结构、标签、权限、更新时间整理好。这首先是产品决策,其次才是技术实现。
表现 B:检索到了错误的内容。 知识库里其实有正确答案,但检索系统返回了不相关的内容,或者返回得太浅、太偏、排序太靠后。模型拿到了“错误的参考资料”,基于这些错误的资料生成了错误的回答。
- 根因:检索相关性或检索路径设计问题
- 解法:改善检索策略。比如从单一路径升级到向量、全文、标量过滤、工具查询的混合搜索,或者优化文档分块、重排逻辑、query 改写逻辑。这是一个发生频率极高的问题,虽然属于偏技术层面的决策,但 PM 必须充分理解这个问题的存在,才能高效推动团队优化。 第二层:模型层问题
表现:答案无中生有。 知识库里的内容检索到了,而且是相关的,但模型在生成回答时“添油加醋”,加入了检索结果中不存在的信息。这就是 F1 中讲过的幻觉问题——模型在“预测下一个词”的过程中,编造了一些听起来合理但并不存在于参考资料中的内容。
- 根因:模型幻觉
- 解法:引用来源设计(让模型标注回答中每个信息点来自哪条参考资料,方便用户验证)、约束生成(在 Prompt 中明确告诉模型“只基于提供的资料回答,如果资料不足,说不知道”)。这些是 Prompt 工程和产品设计层面可以优化的。 第三层:业务层问题
表现:答案正确,但不符合业务场景。 模型基于检索到的内容给出了一个事实上正确的回答,但这个回答不适合当前的业务语境。
举个例子:用户问“如何在当前产品中配置 Embedding 模型的 API KEY”,AI 给出了一个技术上完全正确但充满命令行操作的答案。事实没错,但对于新手用户来说完全看不懂,甚至不知道如何去打开命令行界面。
再比如:用户在一个金融产品中问“这只基金值不值得买”,AI 基于知识库中的基金数据给出了一个详细分析——但公司的要求是不能直接给出投资建议。答案也许“对”,但不合规。
- 根因:回答风格或业务规则不匹配
- 解法:优化 Prompt(调整 System Prompt 中的回答风格和语气要求)、补充业务规则(在 Prompt 或检索逻辑中加入业务约束条件)。
关键判断:大多数问题在数据层
三层归因框架的价值不只是“分清三种情况”,更重要的是它揭示了一个规律:
大多数“AI 答得不好”的问题,根源在数据层,不在模型层。
我们在实践中反复观察到这个比例:
- 当你认真地用这个框架去逐条分析用户反馈时,你会发现 60% 到 80% 的“AI 答错了”,其实是“知识库没覆盖到”或者“检索到了不相关的内容”。
- 真正属于模型幻觉的比例,通常只有 10% 到 20%。
- 业务层问题,则占剩下更少的部分。
但 PM 最常见的反应是什么?“换个更好的模型。”
这就是误诊。你把数据层的问题诊断成了模型层的问题,然后用模型层的解法去治——花了大量时间精力评估模型、切换 API、调整参数,结果发现效果几乎没变。因为你治的不是真正的病。
第六部分:RAG 问题归因决策树
框架有了,怎么用?我给你一棵决策树,下次遇到“AI 答得不好”的用户反馈,按这棵树走就行。
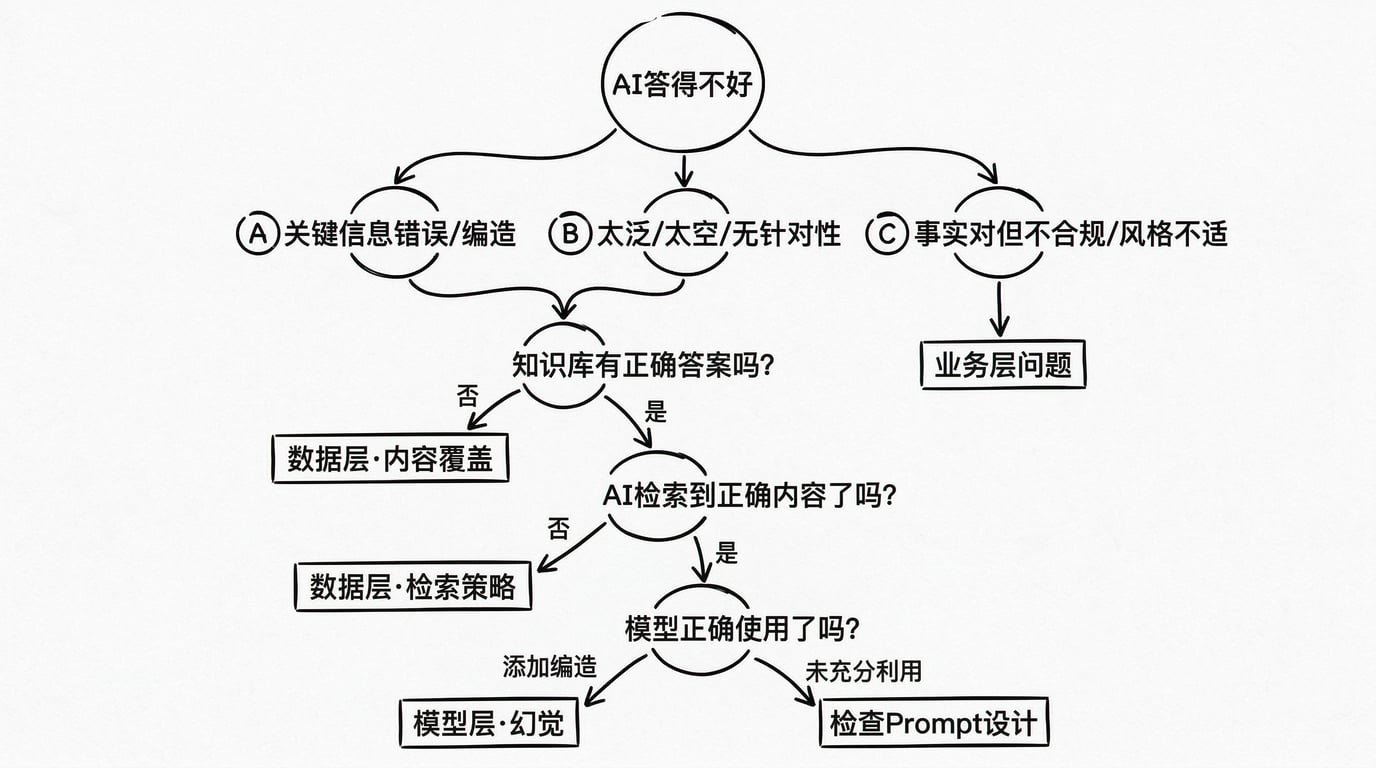
第一步:确认问题是什么。
拿到用户反馈后,先还原现场:用户问了什么问题?AI 给了什么回答?哪里不对?
不对的地方大致分为三种:
- A. 回答中有关键信息是错的或编造的
- B. 回答太泛、太空、没有针对性
- C. 回答的事实没问题,但不合规,或者回答的风格不适合这个场景
如果是 C → 业务层问题,检查 Prompt 和业务规则设计。
如果是 A 或 B → 进入第二步。
第二步:检查知识库中有没有正确答案。
手动去知识库里搜一下:用户这个问题,知识库里有没有对应的正确内容?
- 如果没有 → 数据层问题(内容覆盖)。解法是补充知识库。
- 如果有 → 进入第三步。
第三步:检查 AI 有没有检索到这些正确内容。
查看 AI 这次回答时,实际检索到的内容是什么。(大多数 RAG 系统都可以在后台看到每次检索返回的原始结果。)
- 如果检索到的不是正确内容(检索到了不相关的东西,或者正确内容排在太后面没被使用) → 数据层问题(检索策略)。解法是优化检索逻辑,例如:引入混合搜索。
- 如果检索到的是正确内容 → 进入第四步。
第四步:检查模型有没有正确使用检索到的内容。
正确的内容给到模型了,模型的回答还是不对。这时候看:模型是在正确内容的基础上添加了编造的信息(幻觉),还是没有充分利用检索到的内容?
- 如果是添加了编造信息 → 模型层问题(幻觉)。解法是加强引用来源设计、在 Prompt 中约束“只基于提供的资料回答”。
- 如果是没有充分利用检索到的内容 → 检查 Prompt 设计是否有效引导模型使用检索结果。 这棵决策树的价值在于:它把一个模糊的“AI 答得不好”,变成了一个有明确步骤的排查流程。你不再需要凭直觉猜“是不是模型不行”,而是通过具体的检查步骤,定位到问题出在哪一层。
每一层有不同的解法,你就能把资源投入到真正有效的方向上。
第七部分:总结和思考
让我们回顾一下今天真正要带走的几个判断:
1. RAG 的 R 是 Retrieval,不是 Vector。
不要把 RAG 理解成“向量数据库 + LLM”。全文搜索、过滤搜索、数据库查询、API 调用、Search 工具,本质上都属于广义的 Retrieval。
2. 传统 RAG 和 Agentic RAG 的核心差别,不是复杂度,而是有没有循环。
传统 RAG 往往已经可以很复杂,但通常仍是预先设计好的无环 DAG;Agentic RAG 的关键变化,是流程里开始出现闭环,系统可以自主重试、补搜、改路由、按需调用工具。
3. 评估要跟着流程走。RAGAS 这类指标的核心价值,不是罗列四个名词,而是给流程中间产物和最终输出都建立参照系:Context Recall 看召回有没有漏,Context Precision 看上下文干不干净,Faithfulness 看回答有没有忠于证据,Answer Relevancy 看回答有没有真正解决问题。
4. 混合搜索数据库不是配角,而是流程底座。
混合搜索对传统 RAG 和 Agentic RAG 都重要;数据库的价值,不只是支持这些能力,而是把复杂度尽量内置,减少外部开发者的认知负担和操作难度。
5. 大多数 RAG 问题,仍然出在数据层。
不是“模型不够强”,而是“没搜对”“没搜全”“没把证据组织好”。所以 PM 的第一反应,应该是先回到流程里,找哪一环出了问题。
这节课要留下的印象
如果这节课的所有内容你只记住一句话,记住这句:
用户说“AI 答得不好”时,PM 的第一反应不应该是“换模型”,而应该先问:R 做对了吗?数据准备对了吗?检索路径对了吗?RAG 的上限,不只取决于模型,更取决于你能不能把正确的信息找回来。
课后行动
收集你产品中最近 5 条“AI 答错了”的用户反馈(如果你还没有自己的 AI 产品,可以找你最近使用 AI 工具时遇到的 5 个“答得不好”的案例)。
对每一条反馈,用归因决策树逐步判断:
- 知识库里有没有正确答案? → 没有 → 数据层·内容覆盖
- 有,但 AI 检索到了吗? → 没有 → 数据层·检索策略
- 检索到了,但 AI 的回答和检索内容一致吗? → 不一致 → 模型层·幻觉
- 一致,但不适合业务场景? → 业务层·规则/Prompt
记录每条反馈的归因结果,统计比例。你很可能会发现:大部分问题的根因在数据层,而不在模型层。
把你的归因分析结果带到下节课。P3 中,我们会进入 Agent 记忆系统的设计——另一个看似技术问题、实则产品决策的领域。
延伸阅读
如果你对本期提到的概念想做进一步了解,以下是一些推荐资源:
- 向量数据库:浅入了解向量数据库,解释了向量数据库的基本原理,以及一些常见的基础概念。
- 混合搜索:浅入了解混合搜索,解释了混合搜索的概念,以及执行流程。
- seekdb:seekdb 官网,seekdb 的官方文档。
- RAG:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,RAG 的原始论文,清晰解释了“检索 + 生成”的基本思路。
- RAG 学习:
- 从零开始学习 RAG:https://www.bilibili.com/video/BV1dm41127,LangChain 社区大使张海立老师的 RAG 视频内容。
- RAG From Scratch:langchain-ai/rag-from-scratch,用 notebook 和流程图把 RAG 的各个模块拆得很细。
- Ragas 指标:Ragas 指标,Ragas 指标的官方文档。
下一期预告:P3 · Agent 记忆系统设计——为什么大多数 AI 助手“没有记忆”?给 Agent 加记忆,难的不是“存”,而是“该忘什么”。这又是一个看似技术问题、实则产品决策的领域。